
Job
- Batch 처리에 적합한 컨트롤러로 Pod의 성공적인 완료를 보장합니다.
- 비정상 종료 시 다시 실행
- 정상 종료 시 완료
Kubernetes는 Pod를 Running 중인 상태로 유지합니다.
-> Job을 통해 Batch 처리하는 pod는 작업이 완료되면 종료됩니다.
- pod가 종료될 뿐 삭제되지는 않는다.
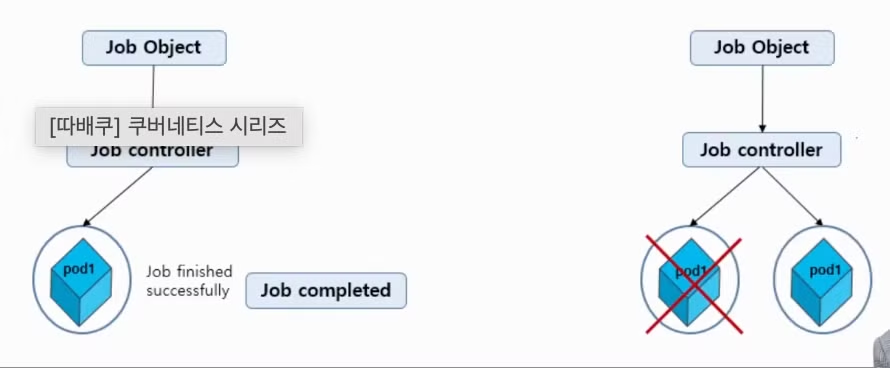
Non-parallel, parallel
- Non-parallel
- 하나의 파드만 실행됩니다.
- Pod가 성공적으로 종료하자마자 즉시 Job이 완료됩니다.
- 고정적인 완료 횟수를 가진 Parallel Job
- .spec.completions에 양수 값을 지정합니다.
- Job은 전체 작업을 나타내며, completions 만큼 성공한 파드가 있을 때 완료됩니다.
- 작업 큐가 있는 Parallel Job
- .spec.parallelism 을 사용합니다.
- Pod는 각자 또는 외부 서비스 간에 조정을 통해 각각의 작업을 결정해야 합니다.
- 각 Pod는 모든 Peer들의 작업이 완료되었는지 여부를 독립적으로 판단할 수 있습니다.
- 하나 이상의 Pod가 성공적으로 종료되고, 모든 파드가 종료되면 잡은 성공적으로 완료됩니다.
- 고정적인 완료 횟수를 설장한 Job인 경우, 병렬로 실행 중인 파드의 수는 남은 완료 수를 초과하지 않습니다.
Pod와 Container 장애 처리
- restartPolicy:
- Never: Job이 실패하면 새로운 Pod를 실행
- onFailure: Job이 실패하면
Job Controller를 재실행파드는 그대로 유지되며 컨테이너가 재실행 - backoffLimit에 지정한 횟수만큼 재실행
📌 참고 :
만약 잡에 restartPolicy = "OnFailure"가 있는 경우 Job Backoff 한계에 도달하면 잡을 실행 중인 파드가 종료됩니다.
이로 인해 잡 실행 파일의 디버깅이 더 어려워질 수 있습니다.
디버깅하거나 로깅 시스템을 사용해서 실패한 작업의 결과를 실수로 손실되지 않도록 하려면 restartPolicy = "Never"로 설정하는 것을 권장한다고 합니다.
apiVersion: batch/v1
kind: Job
metadata:
name: centos-job
spec:
# completions: 5
# parallelism: 2
activeDeadlineSeconds: 5
template:
spec:
containers:
- name: centos-container
image: centos:7
command: ["bash"]
args:
- "-c"
- "echo 'Hello World'; sleep 25; echo 'Bye'"
restartPolicy: Never
# restartPolicy: OnFailure
# backoffLimit: 3- completions : 실행해야 할 Job의 수가 몇 개 인지 지정 (replicaset과 유사)
- parallelism : 병렬성, 동시 running 되는 pod 수
- activeDeadlineSeconds: 지정 시간 내에 Job 완료
- restartPolicy:
- Never: Job이 실패하면 Job Pod를 재실행
- onFailure: Job이 실패하면 Job Controller를 재실행
- backoffLimit에 지정한 횟수만큼 재실행
실행 및 상태 보기
kubectl create -f job-exam.yaml
kubectl describe job centos-job
Job의 종료와 정리
Job이 완료되면 Pod가 더 이상 생성되지 않지만 제거도 되지 않습니다.
→ 완료된 Pod의 Log를 계속 보며 에러, 경고 또는 다른 기타 진단 출력을 확인 가능합니다.
기본적으로 Pod의 실패 또는 컨테이너가 오류로 종료되지 않는 이상, Job은 중단되지 않고 실행되며 backoffLimit까지 연기됩니다. backoffLimit에 도달하면 Job은 실패로 표기되고 실행 중인 모든 Pod는 종료됩니다.
또 다른 종료 방법 (.spec.activeDeadlineSeconds)
activeDeadlineSeconds를 통해 Job의 유효 데드라인을 설정하여 종료시킬 수 있습니다.
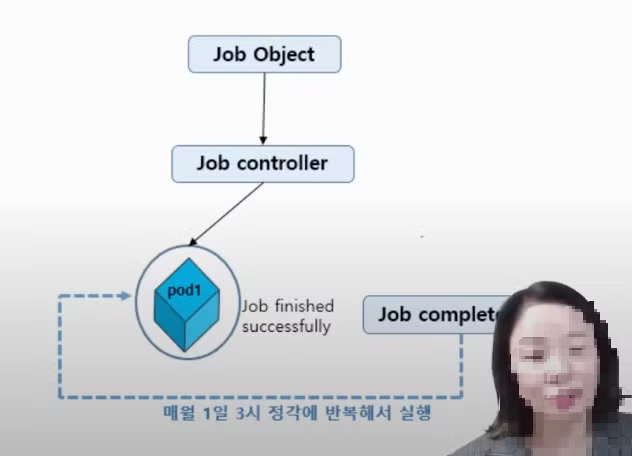
CronJob
- 사용자가 원하는 시간에 JOB 실행 예약을 지원합니다.
- Job 컨트롤러로 실행할 Application Pod를 주기적으로 반복해서 실행
TimeZone 설정
CronJob에 Timezone이 명시되어 있지 않으면, kube-controller-manager는 로컬 타임 존을 기준으로 스케줄을 해석합니다.
.spec.timeZone 에 원하는 타임 존을 설정합니다.
예시 “0 3 1 * *”
- Minutes (0 to 59)
- Hours (0 to 23)
- Day of the month (1 to 31)
- Month (1 to 12)
- Day of the week (0 to 6)
- 0 : Sun
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-exam
spec:
timeZone: 'Asia/Seoul'
schedule: "* * * * *" # 스케줄러 설정
startingDeadlineSeconds: 500
# concurrencyPolicy: Allow
concurrencyPolicy: Forbid
jobTemplate: # Job과 유사함
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- echo Hello; sleep 10; echo Bye
restartPolicy: Never- schedule : 스케줄러 작성 부분
- startingDeadlineSeconds : 500초 안에 실행이 되지 않으면 취소하겠다.
- concurrencyPolicy
- Allow : 동시에 Job이 실행되는 것을 허용 (default)
- Forbid : 동시에 Job이 실행되는 것을 금지
- 이전 잡의 실행이 아직 완료되지 않은 경우, 크론 잡은 새로운 잡 실행을 건너뜁니다.
실행 및 모니터링
kubectl create -f -cronjob-exam.yaml
kubectl get cronjob
kubectl get pods
CronJob의 한계
cronJob은 일정 실행 시간마다 약 1번의 Job Object를 생성합니다.
→ 특정 환경에서는 2 개의 Job이 만들어지거나, Job이 생성되지 않기도 하는 문제가 있습니다.
cronJob Controller는 마지막 일정부터 지금까지 얼마나 많은 cronJob이 누락되었는지 확인합니다.
만약 100회 이상의 일정이 누락되었다면, 잡을 실행하지 않고 에러 로그를 반환합니다.
시작기한 기록
어떤 이유로든 스케줄 된 시간을 놓친 경우 잡의 시작 기한을 초 단위로 기록합니다. 기한이 지나면, cronJob이 Job을 시작하지 않습니다.
→ 기한을 맞추지 못한 잡은 실패한 잡으로 여기며, 다시 실행되지 않는다.
CronJob 유효기간 설정 및 재실행되게 하기
startingDeadlineSeconds 필드 설정을 통해 CronJob 컨트롤러는 예상 잡 생성 시각과 현재 시각의 차이를 측정하고, 시각 차이가 설정한 값보다 커지면 잡 생성 동작을 스킵합니다.
→ 200으로 설정한다면, 예상 잡 생성 시각으로부터 200초까지는 잡이 재생성되어 올바르게 실행될 수 있도록 도와줍니다.
참고자료
잡
잡에서 하나 이상의 파드를 생성하고 지정된 수의 파드가 성공적으로 종료될 때까지 계속해서 파드의 실행을 재시도한다. 파드가 성공적으로 완료되면, 성공적으로 완료된 잡을 추적한다. 지정
kubernetes.io
'Infra > Kubernetes' 카테고리의 다른 글
| Helm 차트란? Helm 구조와 활용법 (0) | 2024.11.14 |
|---|---|
| [Kubernetes] 쿠버네티스 컨테이너 및 파드에 메모리, CPU 할당 - 리소스 제한을 안하면 생기는 문제 (2) | 2024.10.03 |
| [Kubernetes] 쿠버네티스 ReplicaSet, Deployment 리소스 차이 이해하기 (0) | 2024.07.25 |
| [Kubernets] 쿠버네티스 주요 특징 4가지 - Ingress, Service 로드밸런싱 차이 이해하기 (0) | 2024.07.25 |
| GitOps 기반 Kubernetes 배포 자동화: Argo CD & GitHub 활용법 (0) | 2024.05.20 |
Job
- Batch 처리에 적합한 컨트롤러로 Pod의 성공적인 완료를 보장합니다.
- 비정상 종료 시 다시 실행
- 정상 종료 시 완료
Kubernetes는 Pod를 Running 중인 상태로 유지합니다.
-> Job을 통해 Batch 처리하는 pod는 작업이 완료되면 종료됩니다.
- pod가 종료될 뿐 삭제되지는 않는다.
Non-parallel, parallel
- Non-parallel
- 하나의 파드만 실행됩니다.
- Pod가 성공적으로 종료하자마자 즉시 Job이 완료됩니다.
- 고정적인 완료 횟수를 가진 Parallel Job
- .spec.completions에 양수 값을 지정합니다.
- Job은 전체 작업을 나타내며, completions 만큼 성공한 파드가 있을 때 완료됩니다.
- 작업 큐가 있는 Parallel Job
- .spec.parallelism 을 사용합니다.
- Pod는 각자 또는 외부 서비스 간에 조정을 통해 각각의 작업을 결정해야 합니다.
- 각 Pod는 모든 Peer들의 작업이 완료되었는지 여부를 독립적으로 판단할 수 있습니다.
- 하나 이상의 Pod가 성공적으로 종료되고, 모든 파드가 종료되면 잡은 성공적으로 완료됩니다.
- 고정적인 완료 횟수를 설장한 Job인 경우, 병렬로 실행 중인 파드의 수는 남은 완료 수를 초과하지 않습니다.
Pod와 Container 장애 처리
- restartPolicy:
- Never: Job이 실패하면 새로운 Pod를 실행
- onFailure: Job이 실패하면
Job Controller를 재실행파드는 그대로 유지되며 컨테이너가 재실행 - backoffLimit에 지정한 횟수만큼 재실행
📌 참고 :
만약 잡에 restartPolicy = "OnFailure"가 있는 경우 Job Backoff 한계에 도달하면 잡을 실행 중인 파드가 종료됩니다.
이로 인해 잡 실행 파일의 디버깅이 더 어려워질 수 있습니다.
디버깅하거나 로깅 시스템을 사용해서 실패한 작업의 결과를 실수로 손실되지 않도록 하려면 restartPolicy = "Never"로 설정하는 것을 권장한다고 합니다.
apiVersion: batch/v1
kind: Job
metadata:
name: centos-job
spec:
# completions: 5
# parallelism: 2
activeDeadlineSeconds: 5
template:
spec:
containers:
- name: centos-container
image: centos:7
command: ["bash"]
args:
- "-c"
- "echo 'Hello World'; sleep 25; echo 'Bye'"
restartPolicy: Never
# restartPolicy: OnFailure
# backoffLimit: 3- completions : 실행해야 할 Job의 수가 몇 개 인지 지정 (replicaset과 유사)
- parallelism : 병렬성, 동시 running 되는 pod 수
- activeDeadlineSeconds: 지정 시간 내에 Job 완료
- restartPolicy:
- Never: Job이 실패하면 Job Pod를 재실행
- onFailure: Job이 실패하면 Job Controller를 재실행
- backoffLimit에 지정한 횟수만큼 재실행
실행 및 상태 보기
kubectl create -f job-exam.yaml
kubectl describe job centos-job
Job의 종료와 정리
Job이 완료되면 Pod가 더 이상 생성되지 않지만 제거도 되지 않습니다.
→ 완료된 Pod의 Log를 계속 보며 에러, 경고 또는 다른 기타 진단 출력을 확인 가능합니다.
기본적으로 Pod의 실패 또는 컨테이너가 오류로 종료되지 않는 이상, Job은 중단되지 않고 실행되며 backoffLimit까지 연기됩니다. backoffLimit에 도달하면 Job은 실패로 표기되고 실행 중인 모든 Pod는 종료됩니다.
또 다른 종료 방법 (.spec.activeDeadlineSeconds)
activeDeadlineSeconds를 통해 Job의 유효 데드라인을 설정하여 종료시킬 수 있습니다.
CronJob
- 사용자가 원하는 시간에 JOB 실행 예약을 지원합니다.
- Job 컨트롤러로 실행할 Application Pod를 주기적으로 반복해서 실행
TimeZone 설정
CronJob에 Timezone이 명시되어 있지 않으면, kube-controller-manager는 로컬 타임 존을 기준으로 스케줄을 해석합니다.
.spec.timeZone 에 원하는 타임 존을 설정합니다.
예시 “0 3 1 * *”
- Minutes (0 to 59)
- Hours (0 to 23)
- Day of the month (1 to 31)
- Month (1 to 12)
- Day of the week (0 to 6)
- 0 : Sun
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-exam
spec:
timeZone: 'Asia/Seoul'
schedule: "* * * * *" # 스케줄러 설정
startingDeadlineSeconds: 500
# concurrencyPolicy: Allow
concurrencyPolicy: Forbid
jobTemplate: # Job과 유사함
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- echo Hello; sleep 10; echo Bye
restartPolicy: Never- schedule : 스케줄러 작성 부분
- startingDeadlineSeconds : 500초 안에 실행이 되지 않으면 취소하겠다.
- concurrencyPolicy
- Allow : 동시에 Job이 실행되는 것을 허용 (default)
- Forbid : 동시에 Job이 실행되는 것을 금지
- 이전 잡의 실행이 아직 완료되지 않은 경우, 크론 잡은 새로운 잡 실행을 건너뜁니다.
실행 및 모니터링
kubectl create -f -cronjob-exam.yaml
kubectl get cronjob
kubectl get pods
CronJob의 한계
cronJob은 일정 실행 시간마다 약 1번의 Job Object를 생성합니다.
→ 특정 환경에서는 2 개의 Job이 만들어지거나, Job이 생성되지 않기도 하는 문제가 있습니다.
cronJob Controller는 마지막 일정부터 지금까지 얼마나 많은 cronJob이 누락되었는지 확인합니다.
만약 100회 이상의 일정이 누락되었다면, 잡을 실행하지 않고 에러 로그를 반환합니다.
시작기한 기록
어떤 이유로든 스케줄 된 시간을 놓친 경우 잡의 시작 기한을 초 단위로 기록합니다. 기한이 지나면, cronJob이 Job을 시작하지 않습니다.
→ 기한을 맞추지 못한 잡은 실패한 잡으로 여기며, 다시 실행되지 않는다.
CronJob 유효기간 설정 및 재실행되게 하기
startingDeadlineSeconds 필드 설정을 통해 CronJob 컨트롤러는 예상 잡 생성 시각과 현재 시각의 차이를 측정하고, 시각 차이가 설정한 값보다 커지면 잡 생성 동작을 스킵합니다.
→ 200으로 설정한다면, 예상 잡 생성 시각으로부터 200초까지는 잡이 재생성되어 올바르게 실행될 수 있도록 도와줍니다.
참고자료
잡
잡에서 하나 이상의 파드를 생성하고 지정된 수의 파드가 성공적으로 종료될 때까지 계속해서 파드의 실행을 재시도한다. 파드가 성공적으로 완료되면, 성공적으로 완료된 잡을 추적한다. 지정
kubernetes.io
'Infra > Kubernetes' 카테고리의 다른 글
| Helm 차트란? Helm 구조와 활용법 (0) | 2024.11.14 |
|---|---|
| [Kubernetes] 쿠버네티스 컨테이너 및 파드에 메모리, CPU 할당 - 리소스 제한을 안하면 생기는 문제 (2) | 2024.10.03 |
| [Kubernetes] 쿠버네티스 ReplicaSet, Deployment 리소스 차이 이해하기 (0) | 2024.07.25 |
| [Kubernets] 쿠버네티스 주요 특징 4가지 - Ingress, Service 로드밸런싱 차이 이해하기 (0) | 2024.07.25 |
| GitOps 기반 Kubernetes 배포 자동화: Argo CD & GitHub 활용법 (0) | 2024.05.20 |