
Kafka란
대규모 실시간 데이터 스트리밍을 처리하고 관리하는 분산 이벤트 스트리밍 플랫폼입니다.
링크드인(LinkedIn)에서 개발되었으며, 현재 오픈 소스로 제공되어 널리 사용되고 있습니다.
사용 사례
- 로그 및 메트릭 수집
- 대규모 시스템에서 생성되는 로그와 메트릭 데이터를 카프카에 전송하여 중앙에서 실시간으로 수집, 처리, 분석
- 실시간 데이터 파이프라인
- 데이터를 한 시스템에서 다른 시스템으로 실시간으로 전달하는 데이터 파이프라인 구축에 사용됩니다.
- 실시간 스트리밍 분석
- 금융 거래, IoT 센서 데이터 등 실시간 스트리밍 데이터를 처리하고 분석하는 데 사용됩니다.
- 메시지 큐
- 서로 독립적인 서비스 간의 메시지 교환을 위해 사용됩니다.
이벤트 스트리밍 플랫폼이란
이벤트 스트리밍 플랫폼은 데이터를 실시간으로 스트리밍하고 처리하는 시스템을 말합니다.
이러한 플랫폼은 대량의 실시간 데이터를 처리할 수 있어, 로그 수집, 실시간 분석, 모니터링, 데이터 파이프라인 구성 등에 사용됩니다.
3 가지 주요 기능을 결합하여 end-to-end 이벤트 스트리밍을 구현할 수 있다.
- 이벤트 스트림을 지속적으로 발행, 구독합니다.
- 이벤트 스트림을 원하는 만큼 데이터를 내구성 있고 안정적으로 저장합니다. (Kafka Cluster - Broker)
- 이벤트 스트림을 발생하여 처리합니다.
Kafka 주요 개념 및 용어
0. Message Broker
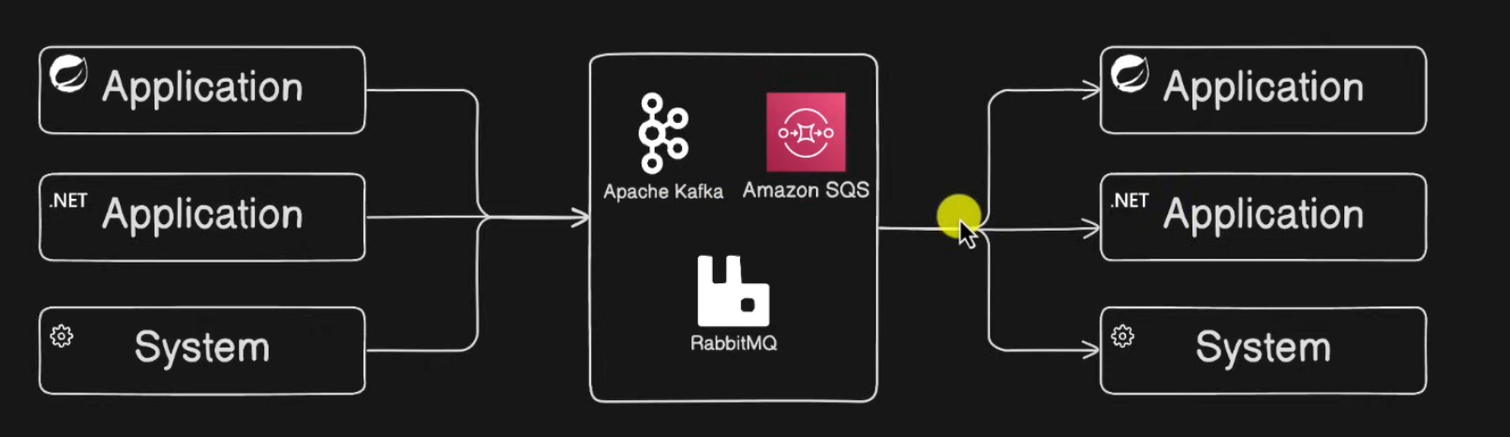
서로 다른 애플리케이션 또는 시스템 간의 통신 및 데이터 교환을 촉진하는 중개 역할을 수행합니다.
주 기능
- 애플리케이션의 생산자를 분리합니다.
- 데이터를 수신하는 애플리케이션 소비자에게 데이터를 전송합니다.
- ⭐ 생산자에서 소비자에게 효율적이고 안정적으로 데이터가 전달되도록 보장하는 중재자 역할을 수행합니다.
메시지 브로커는 먼저 decoupling 되어 애플리케이션이 서로의 존재를 인식할 필요 없이 통신을 할 수 있도록 함.
⇒ 느슨한 결합!!
0. Apache Kafka
Kafka를 메시지 형식의 데이터 저장 및 교환을 관리하기 위해 함께 작동하는 서버라고 합니다.
분산 시스템으로 작동하도록 설계되었으며 클러스터를 통해 수평 확장이 가능합니다. 또한, 허용 오차(Tolerance)를 제공하고
여러 노드에 걸쳐 대량의 데이터를 처리합니다.
1. Producer
메시지(이벤트)를 발행하여 생산하는 주체
- Kafka에게 메시지를 전달합니다.
- Producer is client application that publishes (writes) events to a Kafka cluster
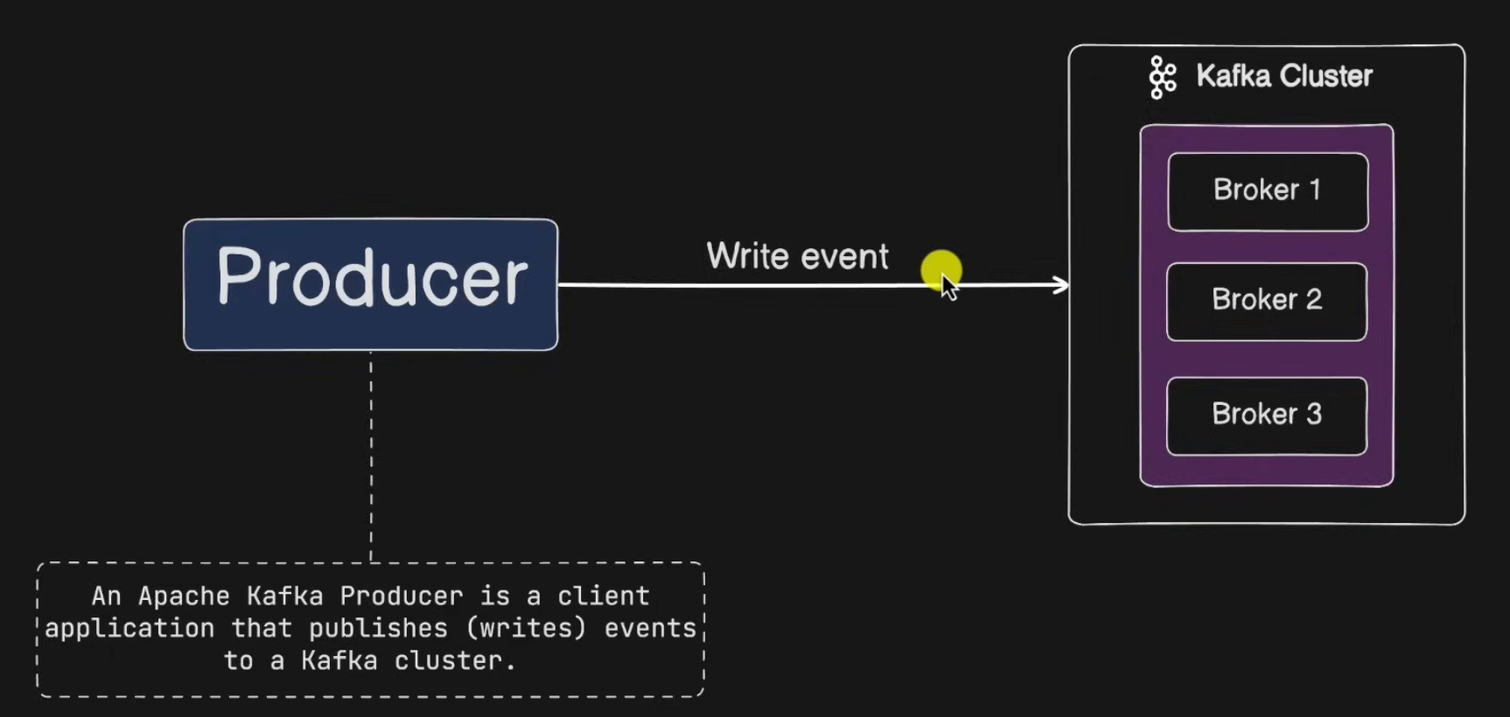
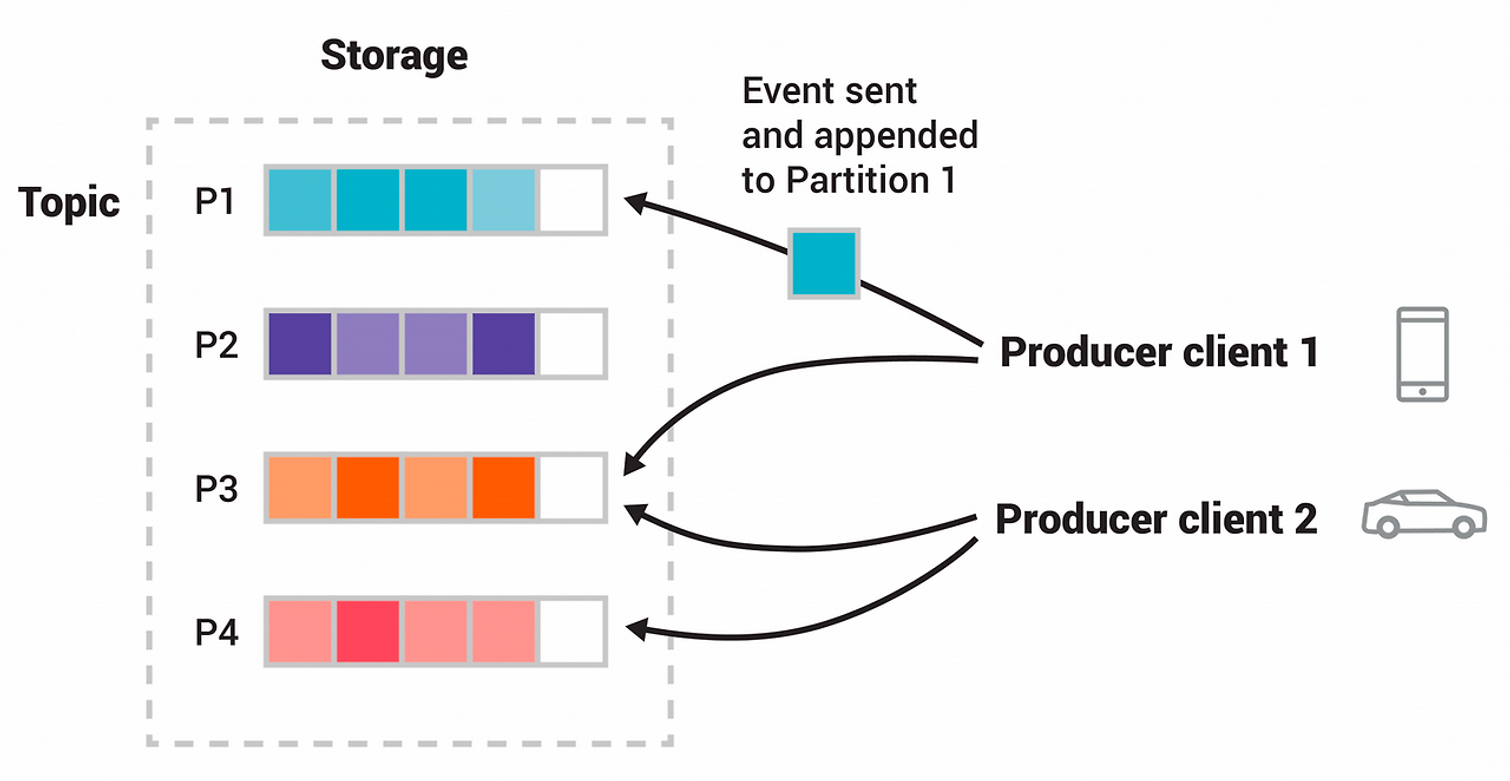
- Producer는 ⭐️ 메시지 전송 시 토픽을 지정합니다.
- 같은 키를 갖는 메시지는 같은 파티션에 저장되며 순서가 유지됩니다.
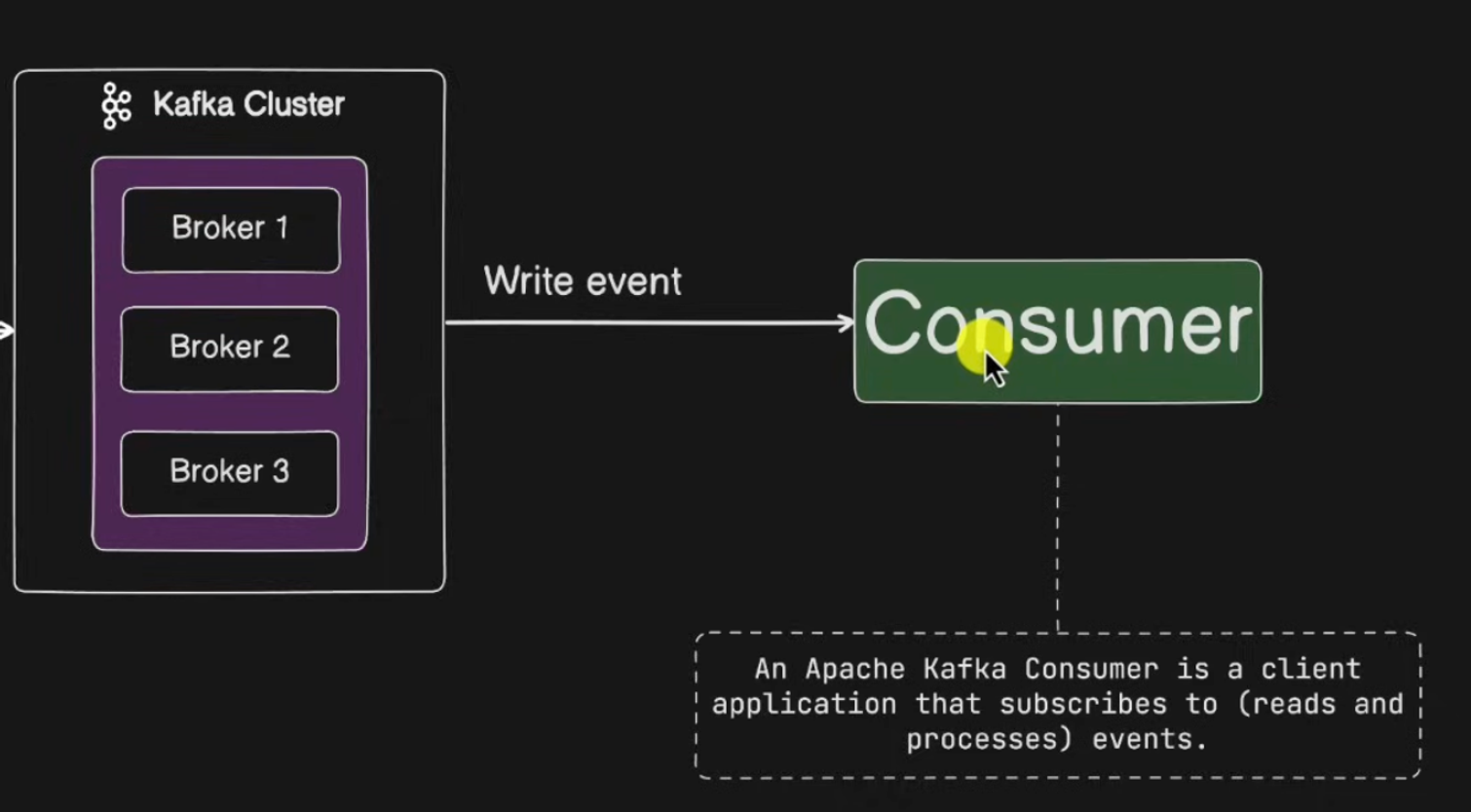
2. Consumer
메시지(이벤트)를 구독하여 소비하는 주체
- Message Topic을 구독하고 등록된 메시지를 처리합니다.
- Kafka로부터 메시지를 전달 받습니다.
- Consumer is a client application that ⭐️ subscribers to (reads and processes) events
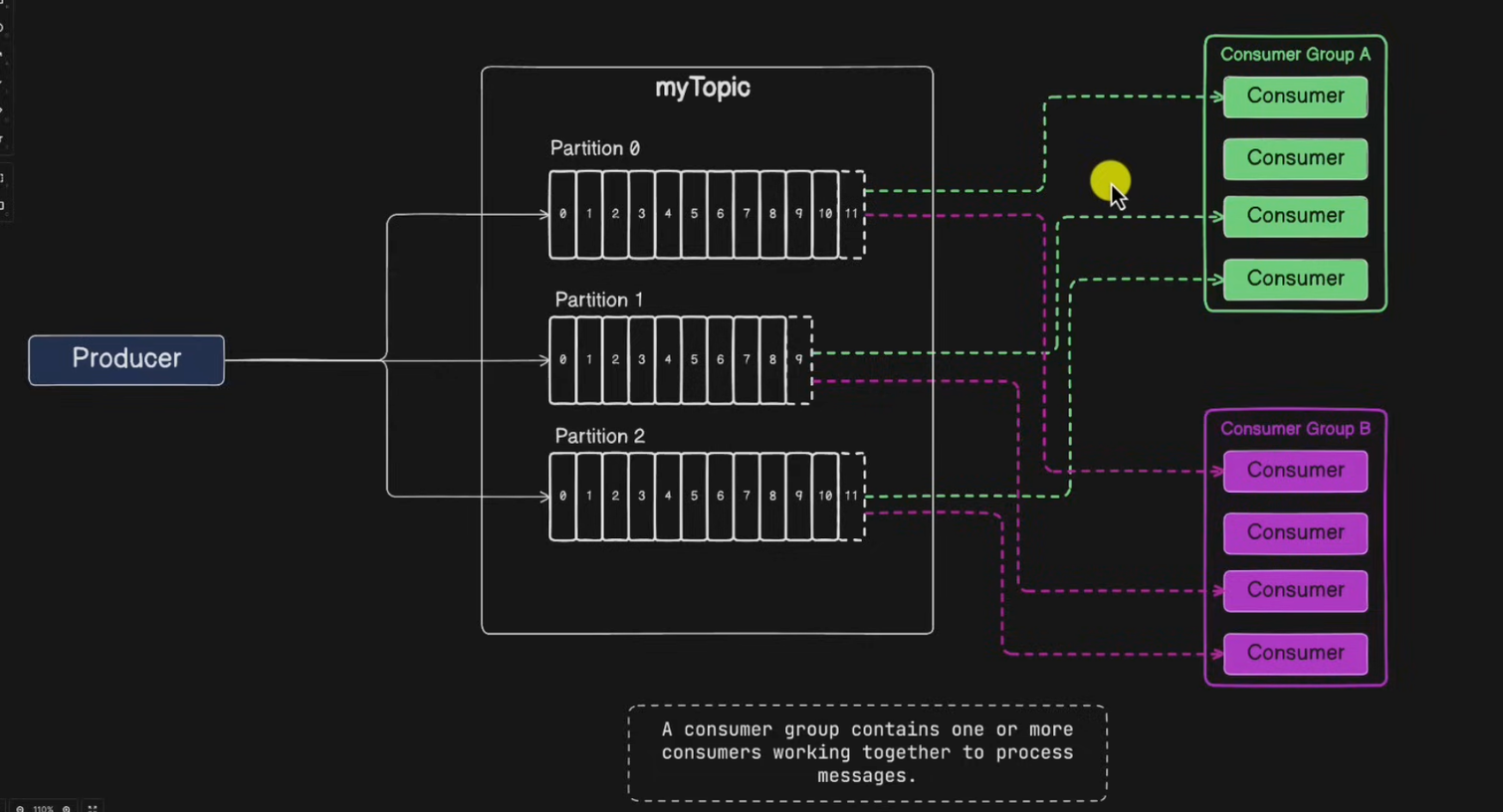
2.1 Consumer Group
Topic의 하나 이상의 파티션에서 메시지를 소비하고 처리하기 위해 함께 작동하는 Kafka 소비자의 논리적 그룹
- Topic의 Partition은 Consumer Group과 1:N 매칭 관계로 ⭐️ 동일 그룹 내 한 개의 Consumer만 연결이 가능합니다.
- 특정 Consumer에 문제가 생겼을 때 Fail Over를 통한 리밸런싱이 가능합니다.
- ⭐️ Topic의 각 파티션을 소비자 그룹 내의 최대 한 명의 소비자에게 할당할 수 있습니다.
- 이를 통해 대용량의 데이터를 병렬 및 확장하여 처리가 가능함
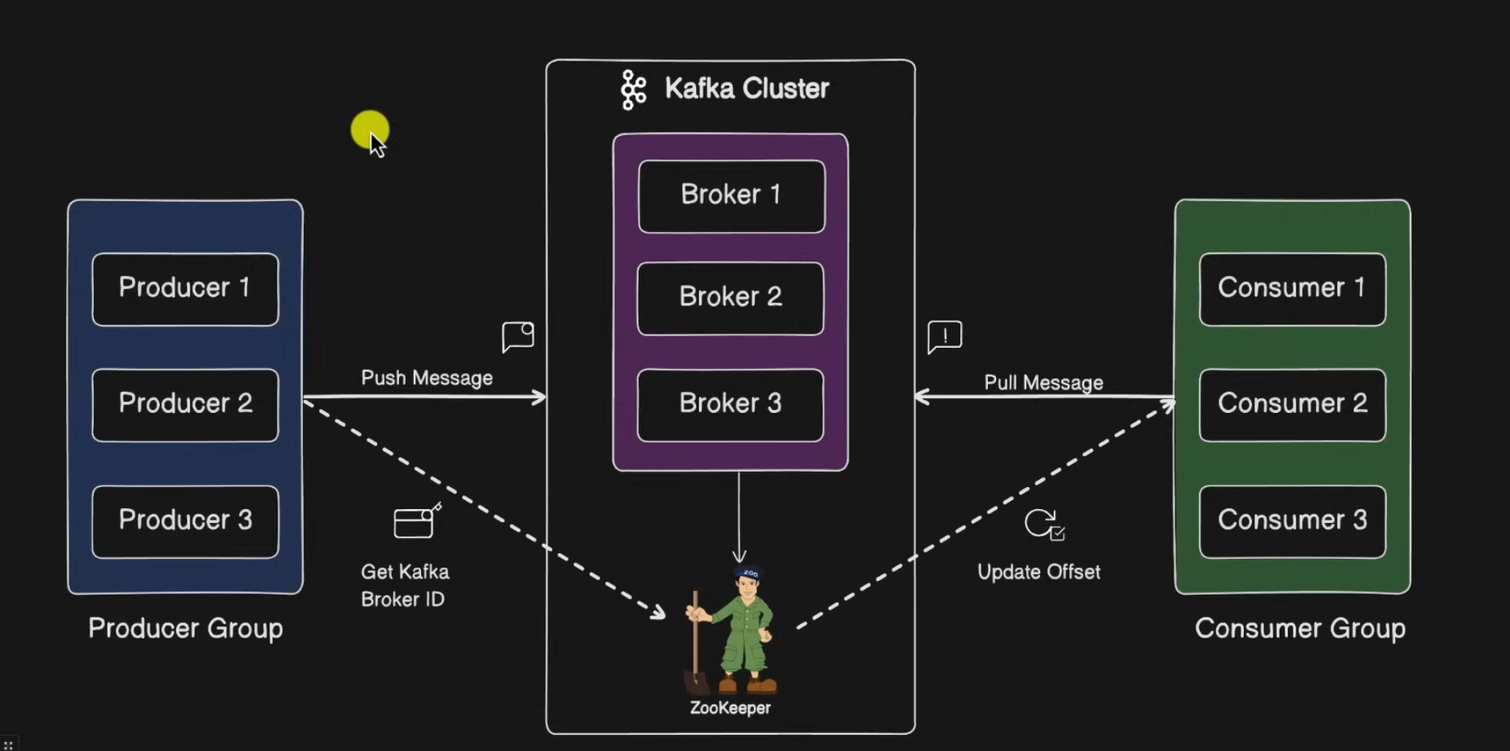
3. Kafka Cluster
Kafka의 브로커들의 모임.
- Kafka는 확장성과 고가용성을 위하여 브로커들이 클러스터로 구성되어 있습니다.
- Broker : 각각의 카프카 서버, 동일 노드에 여러 브로커를 띄울 수 있습니다.
- ⭐️ Kafka Cluster 내에서 로드밸런싱, 데이터 복제, 스트림, 분리를 관리하는 작업을 수행합니다.
- Zookeeper : ⭐️ 카프카 클러스터 정보 및 분산처리 관리 등 메타데이터 저장합니다.
여러 개의 브로커를 사용하는 이유
- 느린 속도 개선
- 대기 시간, 내구성 및 확장성을 통해 여러 데이터 스트림을 별도의 서버에서 처리할 수 있어 데이터 전달의 대기 시간이 감소합니다.
- 여러 서버나 브로커에 걸쳐 복제되므로, 하나가 실패하면 다른 서버에서 데이터가 백업됩니다.
- 확장성을 보장하며 내구성과 가용성을 보장함.
Kafka 메시지 단위
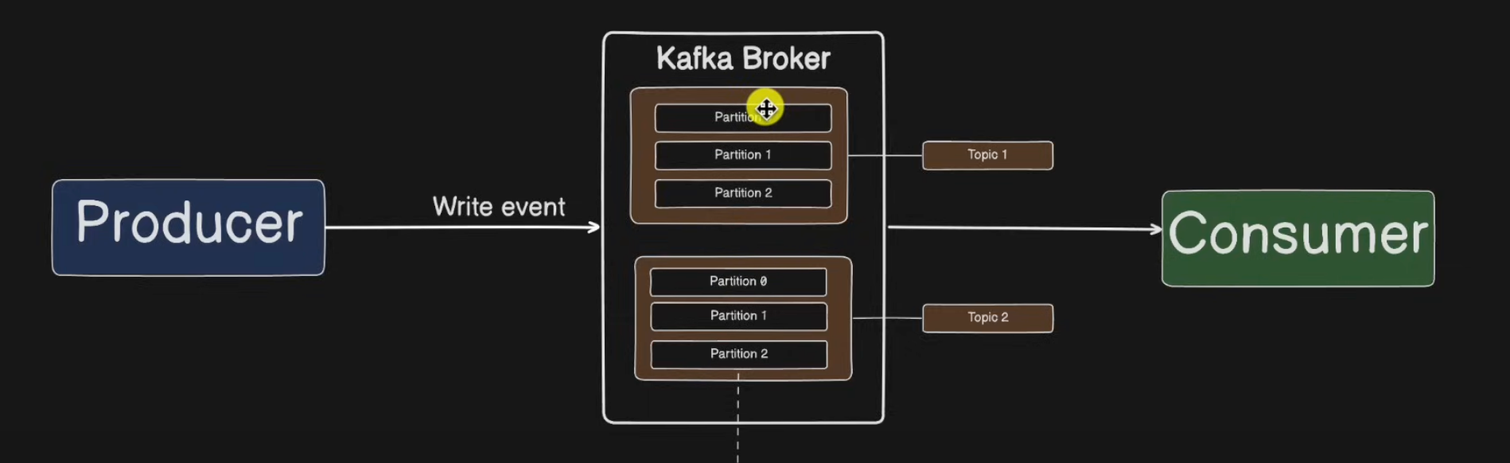
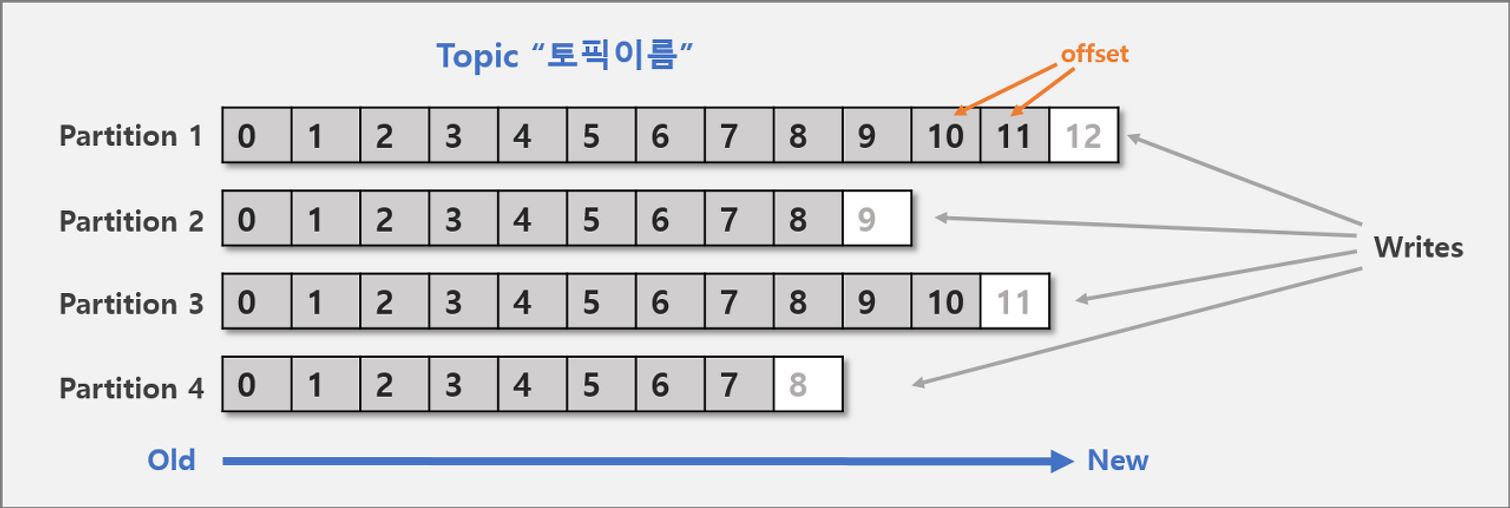
카프카에 저장되는 메시지는 Topic으로 분류 / ⭐️ Topic은 여러 개의 Patition으로 나눠집니다.
Topic
메시지를 구분하는 단위
- 파일 시스템의 폴더와 유사합니다. (ex : 주문용 토픽, 결제용 토픽)
- 생산자가 레코드나 메시지를 게시하는 논리적인 카테고리
Partition
메시지를 저장하는 물리적인 파일
- 한 개의 토픽은 한 개 이상의 파티션으로 구성됩니다.
- ⭐️ Topic을 독립적으로 관리되는 여러 단위의 형태로 수평적으로 나눈 것입니다.
- 병렬성과 확장성의 기본 단위
- 생산자는 서로 다른 파티션에서 동시에 쓸 수 있고, 소비자는 여러 파티션에 작업 부하를 분산하여 Kafka가 더 많은 양의 데이터를 처리할 수 있게 합니다.
a partition is a basic unit of parallelism and scalability.
It is a way of horizontally dividing a topic into multiple independently managed units.
Each partition is a strictly ordered, immutable sequence of records, and it plays a crucial role in the distribution,
parallel processing, and fault tolerance of data within a Kafka cluster
Offset
파티션 내 각 메시지의 저장된 상대적 위치
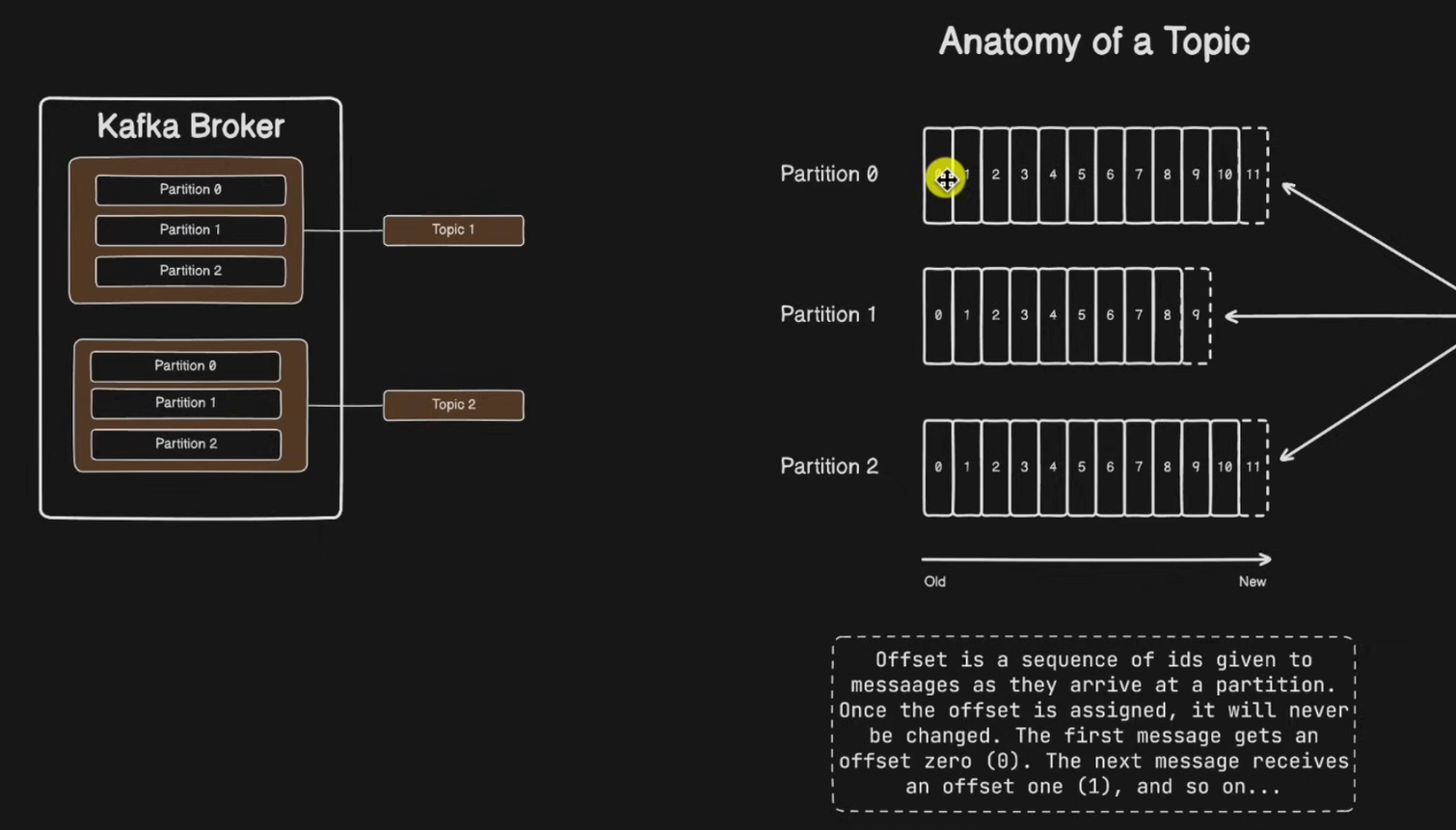
- ⭐️ Kafka Topic의 파티션 내 각 메시지에 할당된 고유 식별자
- Offset을 통해 소비자의 프로세스를 추적하여, 오류가 발생하거나 다시 시작하는 경우에도 특정 지점에서 소비를 재개할 수 있습니다.
- 파티션 내의 각 메시지는 순차적으로 증가하는 오프셋이 할당됩니다.
- 파티션이나 항목 전체에서 고유하므로 하나는 여러 파티션에서 찾을 수 있습니다.
- 파티션 전체에서 고유하지 않지만 하나의 단일 파티션 내에선 고유합니다.
- 메시지가 파티션에 생성될 때 오프셋이 순차적 순서로 할당됨 (불변성)
- 파티션에서 다른 메시지가 생성되거나 소비되더라도, 오프셋은 변경되지 않음
- 소비자는 각 파티션에서 마지막으로 처리된 메시지의 오프셋을 유지하여 프로세스를 추적하므로, 전달이 중단된 시점에서 다시 파티션을 시작할 수 있음
- producer가 넣은 메시지는 파티션의 맨 뒤에 추가
- consumer는 오프셋 기준으로 마지막 커밋 시점부터 메시지를 순서대로 읽어서 처리
CFA (Controller Failover Assignment)란
Kafka에서 ⭐️ 컨트롤러 브로커가 장애가 발생했을 때 새로운 컨트롤러를 할당하는 과정을 의미합니다.
Kafka에서 클러스터 컨트롤러가 변경될 때 사용됩니다.
Kafka 클러스터에서 컨트롤러는 브로커들 간의 조정을 담당하는 중요한 역할을 수행합니다.
특정 브로커가 컨트롤러 역할을 수행하며, 이 브로커는 주키퍼와 통신하여 클러스터의 상태를 관리하고 파티션 리더 선출, 애플리케이션 등 여러 작업을 조정합니다.
컨트롤러 브로커가 실패하거나 클러스터에서 제거될 때, 다른 브로커가 새로운 컨트롤러로 선출됩니다.
이러한 과정에서 새로운 컨트롤러가 클러스터의 리더십을 맡기 위해 할당되는 절차를 CFA라고 합니다.
Kafka 장점
- 다중 프로듀서, 다중 컨슈머가 상호 간섭 없이 메시지를 쓰고 읽어서 처리할 수 있습니다.
- 디스크 기반의 이벤트를 보존합니다.
- 지속해서 보존 가능
- 장애 발생 시 유실 복구 가능 (재처리)
- 파티션 파일은 OS 페이지 캐시를 통해 IO를 메모리에서 처리하여 성능이 유리
- Broker가 수행하는 일 단순성
- 브로커는 컨슈머와 파티션 간 맵핑 관리만 하여 성능에 집중
- 메시지 필터, 메시지 재전송과 같은 일은 프로듀서, 컨슈머에 위임한다.
- Batch 기능을 제공하여 동시 처리량 증가
- Producer : 일정 크기만큼 메시지를 모아서 전송
- Consumer : 최소 크기만큼 메시지를 모아서 읽어옴
- 확장성(scale out)
- 수평 확장이 쉽게 가능 > 브로커,파티션, 컨슈머 추가
참고자료
https://ifuwanna.tistory.com/487
'Infra > Kafka' 카테고리의 다른 글
| [Kafka] Docker Compose를 통해 Kafka 구축하기 - Kraft 모드 (4) | 2024.08.30 |
|---|