
Mysql 쿼리 속도 개선 4 가지
SQL 쿼리에 적용된 실행 계획 확인하는 방법 - explain
explain select * from crew
1. select 실행 시 필요한 column만 뽑기
많은 필드 값을 불러올수록 데이터베이스는 더 많은 로드를 부담합니다.
column 중에 불필요한 값을 가진 필드가 있다면 과감히 제외하고, select 절에 필요한 열만 지정해 불러오는 것이 좋습니다.
2. 조건 부여 시, 기존 DB 값에 별도의 연산을 걸지 않기
-- Inefficient
SELECT m.id, ANY_VALUE(m.title) title, COUNT(r.id) r_count
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
WHERE FLOOR(r.value/2) = 2
GROUP BY m.id;
-- Improved
SELECT m.id, ANY_VALUE(m.title) title, COUNT(r.id) r_count
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
WHERE r.value BETWEEN 4 AND 5
GROUP BY m.id;- inefficient 쿼리의 경우, 모든 Cell 값을 탐색하고, 수식을 건 다음, 조건 충족 여부를 판단하며 Full Table Scan이 이루어집니다.
- Improved 쿼리의 경우는 기존 r.value 가 가지고 있는 index를 그대로 활용할 수 있기 때문에 모든 필드 값을 탐색할 필요가 없습니다.
3. LIKE 사용 시 와일드 카드 문자열 (%) String 앞부분에 배치하지 않기
Index를 활용할 수 있는 value in (…), value =”…”, value LIKE “…%” 와는 다르게,
value LIKE “%…” 는 Full Table Scan을 활용합니다.
그러므로 value LIKE “%…” 는 지양하고 다른 방식으로 조회하는 것이 좋습니다.
-- Inefficient
SELECT g.value genre, COUNT(r.movie_id) r_cnt
FROM rating r
INNER JOIN genre g
ON r.movie_id = g.movie_id
WHERE g.value LIKE "%Comedy"
GROUP BY g.value;
-- Improved(1): value IN (...)
SELECT g.value genre, COUNT(r.movie_id) r_cnt
FROM rating r
INNER JOIN genre g
ON r.movie_id = g.movie_id
WHERE g.value IN ("Romantic Comedy", "Comedy")
GROUP BY g.value;
-- Improved(2): value = "..."
SELECT g.value genre, COUNT(r.movie_id) r_cnt
FROM rating r
INNER JOIN genre g
ON r.movie_id = g.movie_id
WHERE g.value = "Romantic Comedy" OR g.value = "Comedy"
GROUP BY g.value;
-- Improved(3): value LIKE "...%"
-- 모든 문자열을 탐색할 필요가 없어, 가장 좋은 성능을 내었습니다**
SELECT g.value genre, COUNT(r.movie_id) r_cnt
FROM rating r
INNER JOIN genre g
ON r.movie_id = g.movie_id
WHERE g.value LIKE "Romantic%" OR g.value LIKE "Comed%"
GROUP BY g.value;
4. 같은 내용의 조건이라면, Group by 연산 시에는 Having 보다 Where 절에 사용하기
- 쿼리 실행 순서에 따라, Where 절이 Having 절보다 먼저 실행됩니다.
- 따라서 Where 절로 미리 데이터 크기를 작게 만들어 Group by에서 다루는 데이터 크기가 작아져 효율적인 연산이 가능합니다.
-- Inefficient
SELECT m.id, COUNT(r.id) AS rating_cnt, AVG(r.value) AS avg_rating
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
GROUP BY id
HAVING m.id > 1000;
-- Improved
SELECT m.id, COUNT(r.id) AS rating_cnt, AVG(r.value) AS avg_rating
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
WHERE m.id > 1000
GROUP BY id ;
MySQL 성능 최적화
인덱스 사용하는 이유
조회 성능을 개선하기 위해서는 디스크 I/O를 줄이는 것이 중요합니다.
인덱스를 사용하는 경우 조회 성능은 개선이 될 수 있지만, 데이터 수정, 삭제, 생성에 느려지는 문제가 있음
→ 하지만, 웬만한 웹 서비스에서는 R vs CUD 가 8:2, 9:1 비율로 사용되고 있어 큰 문제가 되지 않습니다.
Order by, Group by에서 이점이 있음
Order by 예시
select *
from crew
where nickname >= "매트" and nickname <= "토르"
order by nickname;- Index가 있으면 (nickname)데이터가 정렬된 인덱스 파일을 기준으로 정렬합니다.
Group by 예시
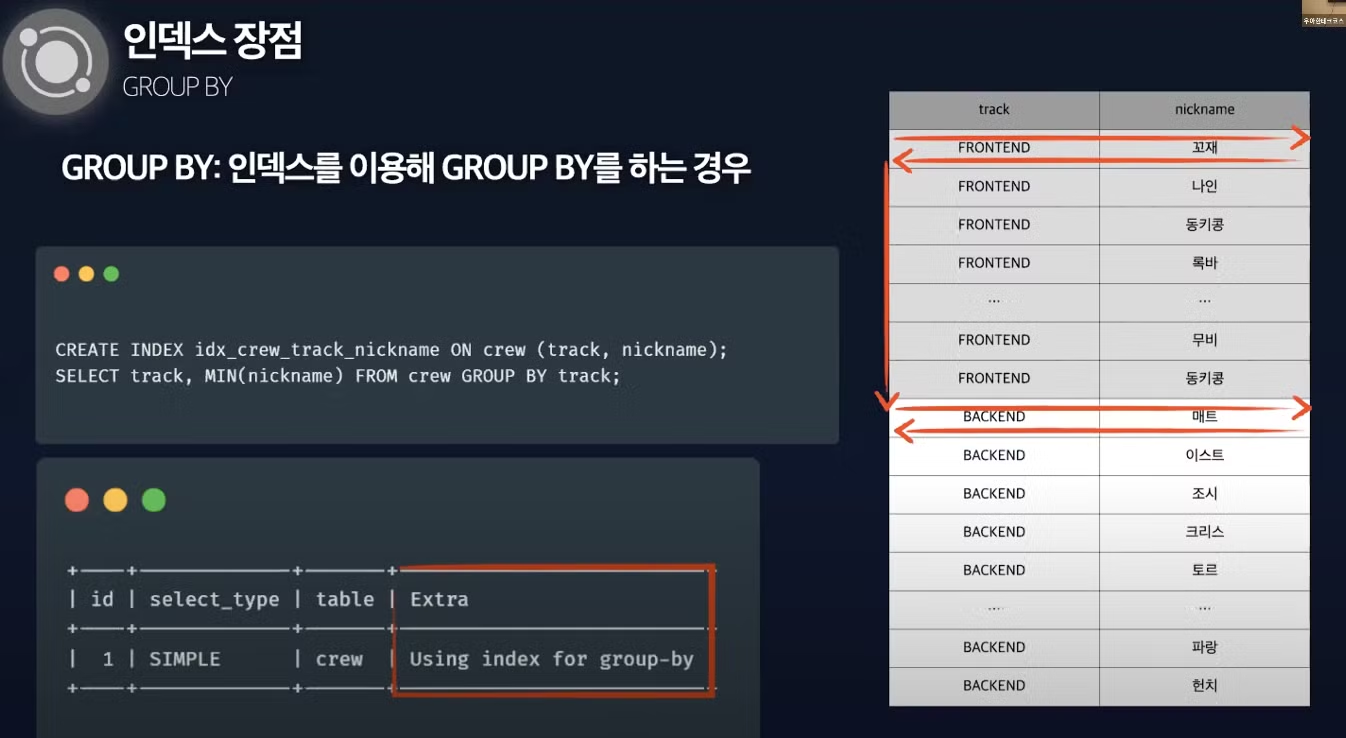
select track, MIN(nickname) from crew group by track;- 인덱스가 존재하는 경우 track-frontend 중 가장 앞에 있는 데이터를 읽고 나머지 데이터는 읽지 않고 track-backend를 넘어가 디스크 I/O를 줄입니다.
인덱스 실행 계획 이해하기
All (Full Table Scan)
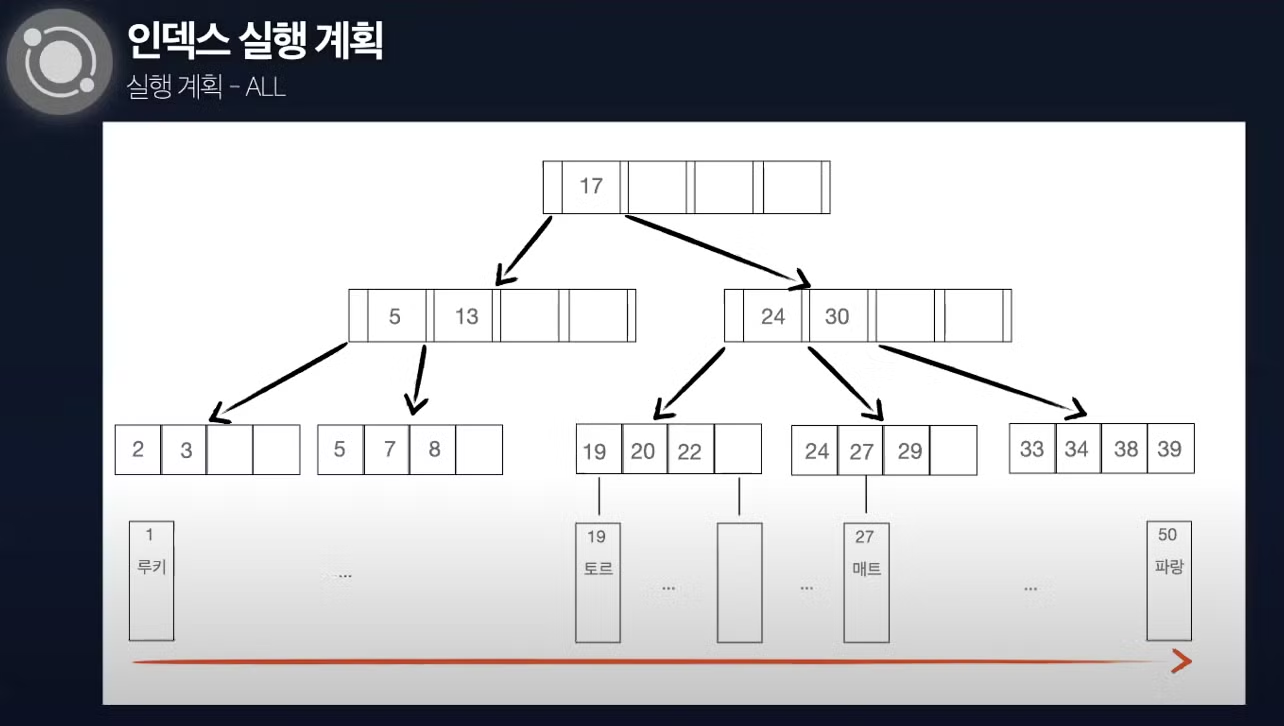
- 모든 데이터를 조회하는 작업 (성능이 좋지 않음)
- 인덱스가 없는 경우 full table scan이 일어남
- 인덱스가 있지만, 읽고자 하는 데이터가 전체 데이터의 25% 이하이면 full table scan이 일어남
Range (range table scan)
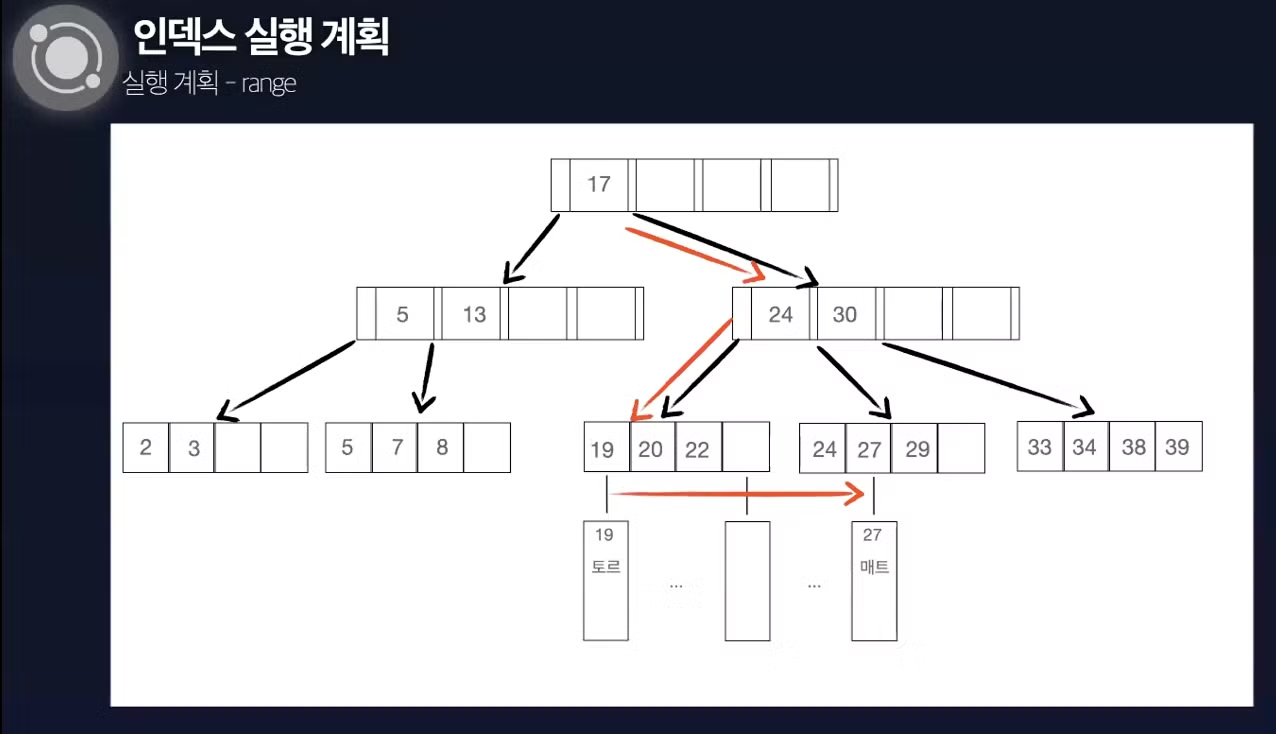
- 범위 설정을 통해 탐색할 데이터의 범위를 줄여 디스크 I/O를 줄임
Index (index full scan)
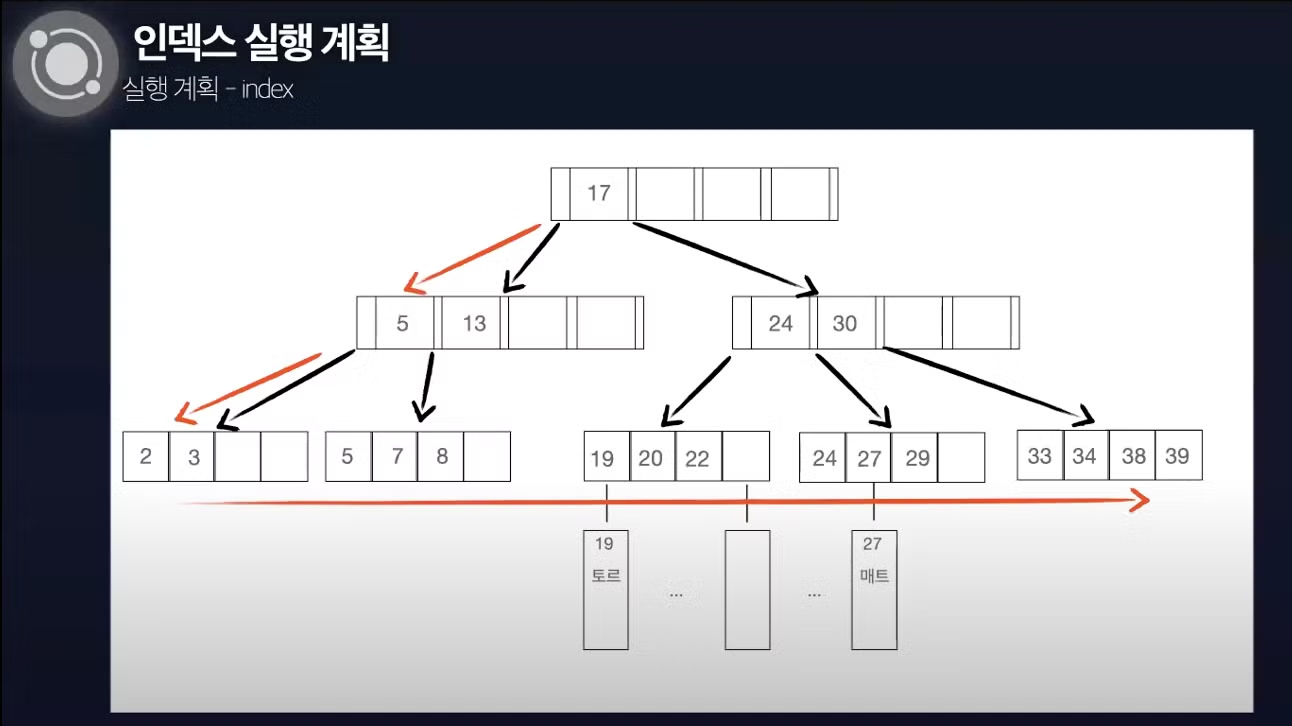
- 인덱스 전체를 탐색하여 데이터를 조회함
- full table scan보다 파일 크기가 작아 효율적이긴 하지만 range table scan보다 비효율적임
인덱스 적용 사례 1
어느 컬럼에 인덱스를 걸어야 할까?
1. 서비스의 특성상 무엇에 대한 조회가 많이 일어나는지 파악합니다.
create index idx_crew_nickname on crew (nickname);
2. 카디널리티가 높은 칼럼에 대해 인덱스를 생성합니다.
인덱스 적용 사례 2 (복합 인덱스)
복합 인덱스란
두 개 이상의 칼럼을 합쳐서 만들어진 인덱스
하나의 컬럼으로 인덱스를 만들었을 때 보다 더 적은 데이터 분포를 보여 탐색할 데이터 수가 줄어듭니다.
→ 첫 번째 컬럼을 기준으로 데이터를 좁힌 후, 두 번째 컬럼을 추가로 고려하여 탐색 범위를 더욱 좁힙니다.
복합 인덱스 생성 시 컬럼의 순서에 따라 생성되므로 어느 컬럼으로 먼저 더 데이터 범위를 좁힐지 생각해야 합니다.
alter table crew add index idx_crew_age_nickname (age, nickname);
복합 인덱스 사용 가능
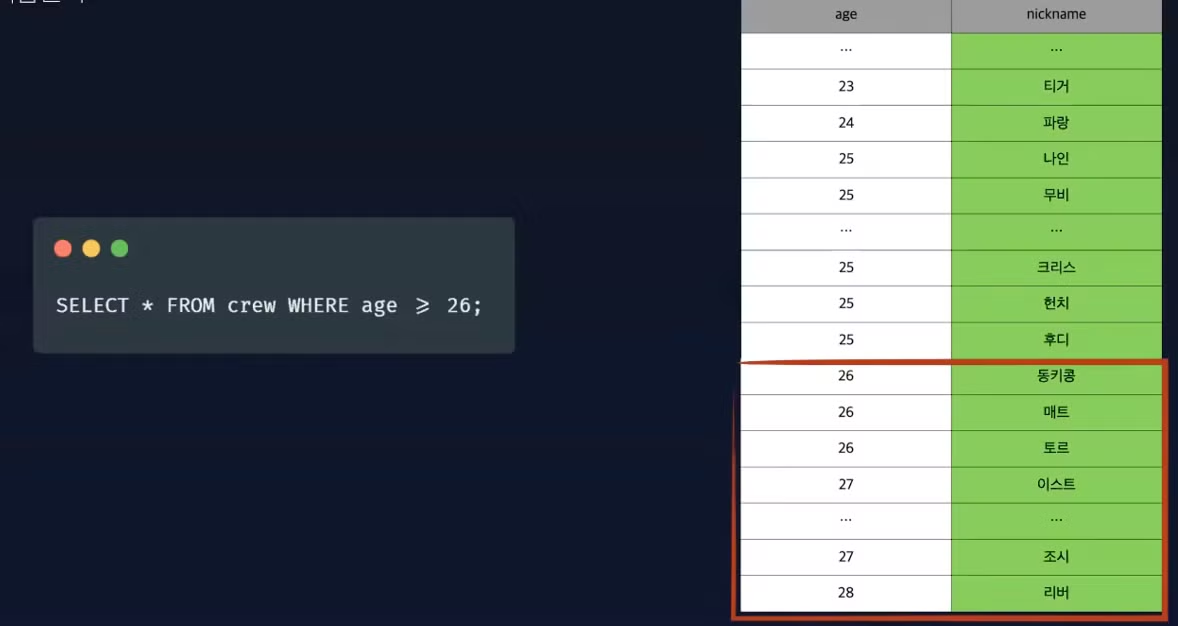
복합 인덱스 사용 가능
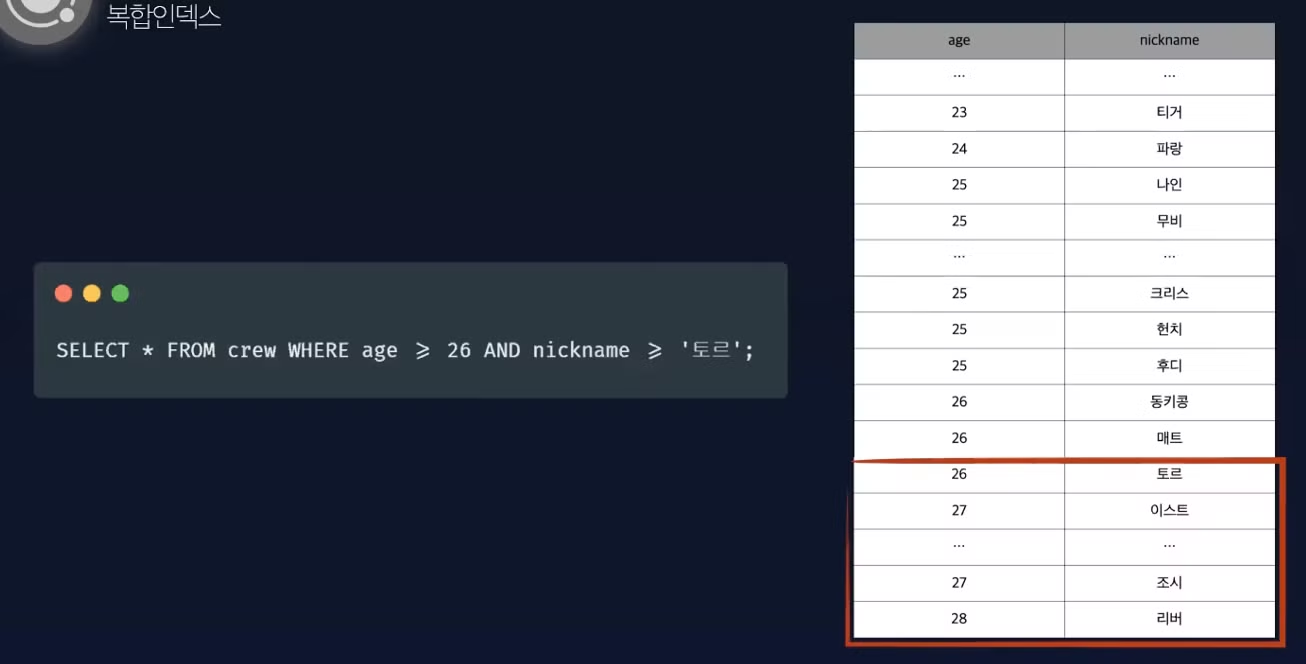
복합 인덱스 사용 불가능
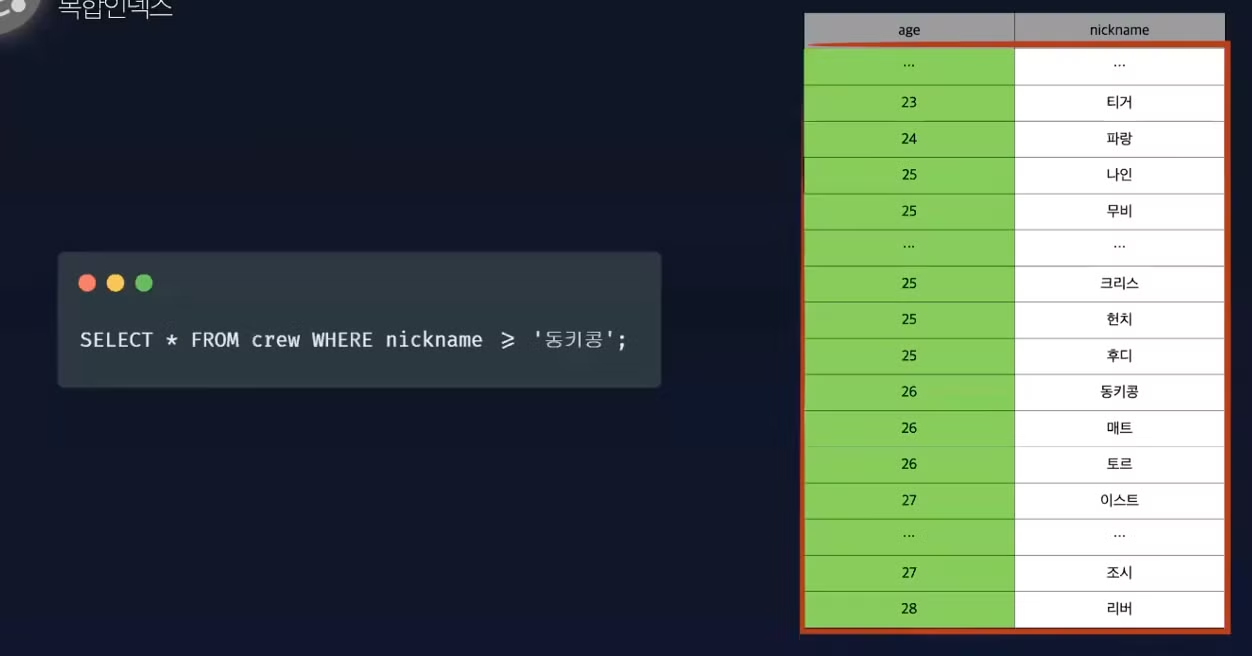
인덱스 적용 사례 3 (커버링 인덱스)
인덱스를 사용하여 처리하는 쿼리 중 가장 큰 부하를 차지하는 부분은 인덱스 검색에서 일치하는 키 값의 레코드를 읽는 것입니다.
→ 최악의 경우 N 개의 인덱스 검색시 N번의 디스크 I/O가 발생하는 것
커버링 인덱스란
인덱스로 설정한 컬럼만 읽어 쿼리를 모두 처리할 수 있는 인덱스를 의미합니다.
→ 불필요한 디스크 I/O를 줄여 조회 시간을 단축합니다.
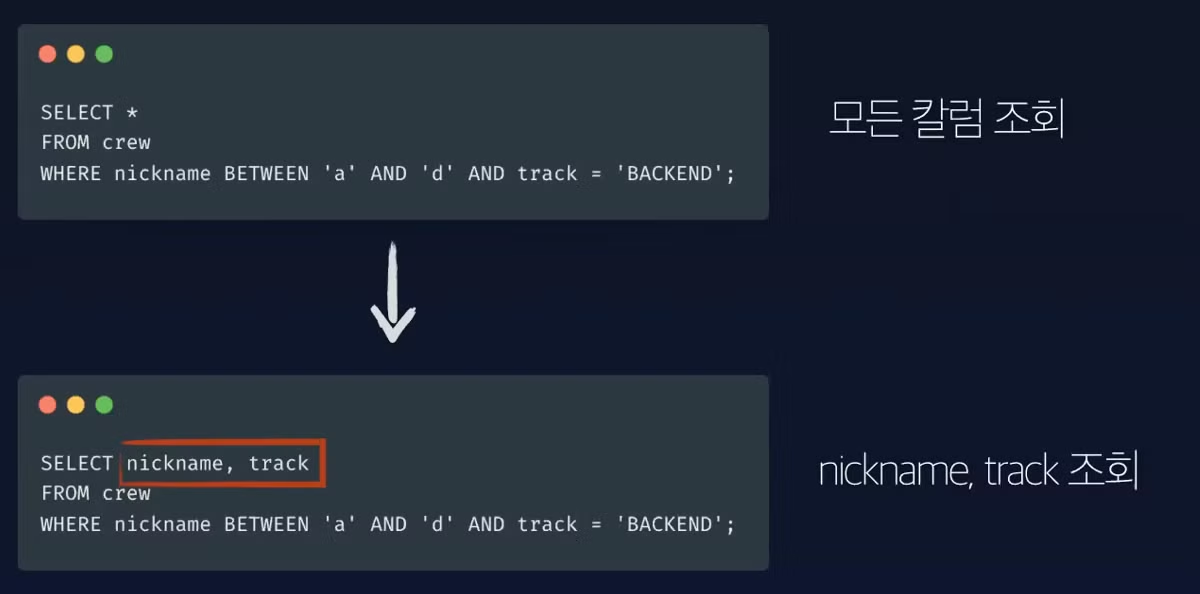
복합 인덱스가 아닌 PK도 조회한다면?

- InnoDB Secondary 인덱스의 구조로, 리프 노드에는 실제 레코드 주소가 아닌 클러스터드 인덱스가 걸린 PK를 주소로 가집니다.
- 그러므로 복합 인덱스와 PK 인덱스 모두 사용 가능합니다.
참고자료
[10분 테코톡] 매트, 토르의 MySQL 성능 최적화
'DB > MySQL' 카테고리의 다른 글
| 데이터베이스 단일 인덱스와 복합 인덱스의 차이와 활용법 (0) | 2025.01.25 |
|---|---|
| MySQL 인덱스를 통한 성능 최적화: 효과적인 인덱스 설계와 쿼리 튜닝 방법 (0) | 2025.01.25 |
| 데이터베이스 성능 문제 해결: SQL 최적화와 쿼리 튜닝 방법 (0) | 2024.12.07 |
| [Mysql] mysql select 쿼리 실행 순 익히기, 스키마 create&drop (0) | 2023.10.21 |
Mysql 쿼리 속도 개선 4 가지
SQL 쿼리에 적용된 실행 계획 확인하는 방법 - explain
explain select * from crew
1. select 실행 시 필요한 column만 뽑기
많은 필드 값을 불러올수록 데이터베이스는 더 많은 로드를 부담합니다.
column 중에 불필요한 값을 가진 필드가 있다면 과감히 제외하고, select 절에 필요한 열만 지정해 불러오는 것이 좋습니다.
2. 조건 부여 시, 기존 DB 값에 별도의 연산을 걸지 않기
-- Inefficient
SELECT m.id, ANY_VALUE(m.title) title, COUNT(r.id) r_count
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
WHERE FLOOR(r.value/2) = 2
GROUP BY m.id;
-- Improved
SELECT m.id, ANY_VALUE(m.title) title, COUNT(r.id) r_count
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
WHERE r.value BETWEEN 4 AND 5
GROUP BY m.id;- inefficient 쿼리의 경우, 모든 Cell 값을 탐색하고, 수식을 건 다음, 조건 충족 여부를 판단하며 Full Table Scan이 이루어집니다.
- Improved 쿼리의 경우는 기존 r.value 가 가지고 있는 index를 그대로 활용할 수 있기 때문에 모든 필드 값을 탐색할 필요가 없습니다.
3. LIKE 사용 시 와일드 카드 문자열 (%) String 앞부분에 배치하지 않기
Index를 활용할 수 있는 value in (…), value =”…”, value LIKE “…%” 와는 다르게,
value LIKE “%…” 는 Full Table Scan을 활용합니다.
그러므로 value LIKE “%…” 는 지양하고 다른 방식으로 조회하는 것이 좋습니다.
-- Inefficient
SELECT g.value genre, COUNT(r.movie_id) r_cnt
FROM rating r
INNER JOIN genre g
ON r.movie_id = g.movie_id
WHERE g.value LIKE "%Comedy"
GROUP BY g.value;
-- Improved(1): value IN (...)
SELECT g.value genre, COUNT(r.movie_id) r_cnt
FROM rating r
INNER JOIN genre g
ON r.movie_id = g.movie_id
WHERE g.value IN ("Romantic Comedy", "Comedy")
GROUP BY g.value;
-- Improved(2): value = "..."
SELECT g.value genre, COUNT(r.movie_id) r_cnt
FROM rating r
INNER JOIN genre g
ON r.movie_id = g.movie_id
WHERE g.value = "Romantic Comedy" OR g.value = "Comedy"
GROUP BY g.value;
-- Improved(3): value LIKE "...%"
-- 모든 문자열을 탐색할 필요가 없어, 가장 좋은 성능을 내었습니다**
SELECT g.value genre, COUNT(r.movie_id) r_cnt
FROM rating r
INNER JOIN genre g
ON r.movie_id = g.movie_id
WHERE g.value LIKE "Romantic%" OR g.value LIKE "Comed%"
GROUP BY g.value;
4. 같은 내용의 조건이라면, Group by 연산 시에는 Having 보다 Where 절에 사용하기
- 쿼리 실행 순서에 따라, Where 절이 Having 절보다 먼저 실행됩니다.
- 따라서 Where 절로 미리 데이터 크기를 작게 만들어 Group by에서 다루는 데이터 크기가 작아져 효율적인 연산이 가능합니다.
-- Inefficient
SELECT m.id, COUNT(r.id) AS rating_cnt, AVG(r.value) AS avg_rating
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
GROUP BY id
HAVING m.id > 1000;
-- Improved
SELECT m.id, COUNT(r.id) AS rating_cnt, AVG(r.value) AS avg_rating
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
WHERE m.id > 1000
GROUP BY id ;
MySQL 성능 최적화
인덱스 사용하는 이유
조회 성능을 개선하기 위해서는 디스크 I/O를 줄이는 것이 중요합니다.
인덱스를 사용하는 경우 조회 성능은 개선이 될 수 있지만, 데이터 수정, 삭제, 생성에 느려지는 문제가 있음
→ 하지만, 웬만한 웹 서비스에서는 R vs CUD 가 8:2, 9:1 비율로 사용되고 있어 큰 문제가 되지 않습니다.
Order by, Group by에서 이점이 있음
Order by 예시
select *
from crew
where nickname >= "매트" and nickname <= "토르"
order by nickname;- Index가 있으면 (nickname)데이터가 정렬된 인덱스 파일을 기준으로 정렬합니다.
Group by 예시
select track, MIN(nickname) from crew group by track;- 인덱스가 존재하는 경우 track-frontend 중 가장 앞에 있는 데이터를 읽고 나머지 데이터는 읽지 않고 track-backend를 넘어가 디스크 I/O를 줄입니다.
인덱스 실행 계획 이해하기
All (Full Table Scan)
- 모든 데이터를 조회하는 작업 (성능이 좋지 않음)
- 인덱스가 없는 경우 full table scan이 일어남
- 인덱스가 있지만, 읽고자 하는 데이터가 전체 데이터의 25% 이하이면 full table scan이 일어남
Range (range table scan)
- 범위 설정을 통해 탐색할 데이터의 범위를 줄여 디스크 I/O를 줄임
Index (index full scan)
- 인덱스 전체를 탐색하여 데이터를 조회함
- full table scan보다 파일 크기가 작아 효율적이긴 하지만 range table scan보다 비효율적임
인덱스 적용 사례 1
어느 컬럼에 인덱스를 걸어야 할까?
1. 서비스의 특성상 무엇에 대한 조회가 많이 일어나는지 파악합니다.
create index idx_crew_nickname on crew (nickname);
2. 카디널리티가 높은 칼럼에 대해 인덱스를 생성합니다.
인덱스 적용 사례 2 (복합 인덱스)
복합 인덱스란
두 개 이상의 칼럼을 합쳐서 만들어진 인덱스
하나의 컬럼으로 인덱스를 만들었을 때 보다 더 적은 데이터 분포를 보여 탐색할 데이터 수가 줄어듭니다.
→ 첫 번째 컬럼을 기준으로 데이터를 좁힌 후, 두 번째 컬럼을 추가로 고려하여 탐색 범위를 더욱 좁힙니다.
복합 인덱스 생성 시 컬럼의 순서에 따라 생성되므로 어느 컬럼으로 먼저 더 데이터 범위를 좁힐지 생각해야 합니다.
alter table crew add index idx_crew_age_nickname (age, nickname);
복합 인덱스 사용 가능
복합 인덱스 사용 가능
복합 인덱스 사용 불가능
인덱스 적용 사례 3 (커버링 인덱스)
인덱스를 사용하여 처리하는 쿼리 중 가장 큰 부하를 차지하는 부분은 인덱스 검색에서 일치하는 키 값의 레코드를 읽는 것입니다.
→ 최악의 경우 N 개의 인덱스 검색시 N번의 디스크 I/O가 발생하는 것
커버링 인덱스란
인덱스로 설정한 컬럼만 읽어 쿼리를 모두 처리할 수 있는 인덱스를 의미합니다.
→ 불필요한 디스크 I/O를 줄여 조회 시간을 단축합니다.
복합 인덱스가 아닌 PK도 조회한다면?
- InnoDB Secondary 인덱스의 구조로, 리프 노드에는 실제 레코드 주소가 아닌 클러스터드 인덱스가 걸린 PK를 주소로 가집니다.
- 그러므로 복합 인덱스와 PK 인덱스 모두 사용 가능합니다.
참고자료
[10분 테코톡] 매트, 토르의 MySQL 성능 최적화
'DB > MySQL' 카테고리의 다른 글
| 데이터베이스 단일 인덱스와 복합 인덱스의 차이와 활용법 (0) | 2025.01.25 |
|---|---|
| MySQL 인덱스를 통한 성능 최적화: 효과적인 인덱스 설계와 쿼리 튜닝 방법 (0) | 2025.01.25 |
| 데이터베이스 성능 문제 해결: SQL 최적화와 쿼리 튜닝 방법 (0) | 2024.12.07 |
| [Mysql] mysql select 쿼리 실행 순 익히기, 스키마 create&drop (0) | 2023.10.21 |