
Index
인덱스 파일은 데이터베이스에서 쿼리 성능을 향상시키기 위해 테이블의 특정 컬럼 값과 해당 행의 위치(Pointer)를 저장합니다.
인덱스는 테이블의 데이터를 효율적으로 검색하기 위한 자료구조를 활용합니다. (B-Tree, Hash)
Indexed Column Value
인덱스가 설정된 컬럼의 실제 값들이 저장됩니다.
해당 값을 이용해 데이터베이스가 특정 행을 찾는 데 필요한 정보로 사용합니다.
Indexed Column Value: 101, 102, 103, 104, ...
Row Pointer
인덱스 파일에는 해당 인덱스 키 값이 테이블의 어느 행에 위치하는지에 대한 정보를 나타내는 포인터가 함께 저장됩니다.
해당 포인터는 테이블의 실제 데이터 행을 가리킵니다.
Indexed Column Value: 101 -> Row 5
Indexed Column Value: 102 -> Row 2
Indexed Column Value: 103 -> Row 7
복합 인덱스인 경우
복합 인덱스의 인덱스 파일에는 각 컬럼의 값이 순서대로 결합된 형태로 저장됩니다.
인덱스 파일은 첫 번째 컬럼 값에 따라 정렬되며, 그다음 두 번째 컬럼 값에 따라 정렬됩니다.
(department, job_title) -> Row Pointer
(HR, Manager) -> Row 5
(HR, Analyst) -> Row 2
(Sales, Manager) -> Row 7
Clustered Index
클러스터드 인덱스는 데이터가 테이블에 물리적으로 저장되는 순서를 정의합니다.
- 클러스터형 인덱스는 특정 컬럼을 기준으로 데이터들을 정렬시킵니다.
- id가 클러스터형 인덱스로 지정되어, id 값을 기준으로 데이터들이 정렬되어 있습니다.
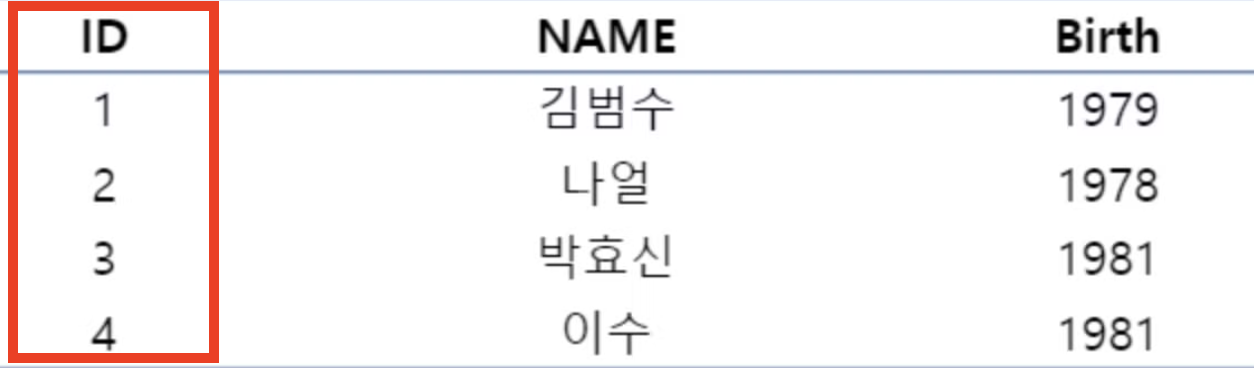
테이블 데이터는 오직 한 가지의 방법으로만 정렬되기에, 테이블 당 하나의 클러스터 형 인덱스만 존재할 수 있습니다.
- Primary Key의 제약 조건은 클러스터 된 인덱스를 자동으로 생성합니다.
어떤 경우에 생성해야 하는지
- 테이블 데이터가 자주 업데이트 되지 않는 경우
- 중간에 새로운 데이터가 들어오는데 뒤에 수백만 개의 데이터가 존재하는 경우, index가 군집화되어 있으므로 모든 데이터가 한 칸씩 이동하게 되어 많은 비용이 발생합니다.
- 항상 정렬된 방식으로 데이터를 반환하는 경우
- 테이블이 이미 정렬되어 있기에, Order by 절을 활용하지 않아도 된다.
- 읽기 작업이 많은 경우
Non Clustered
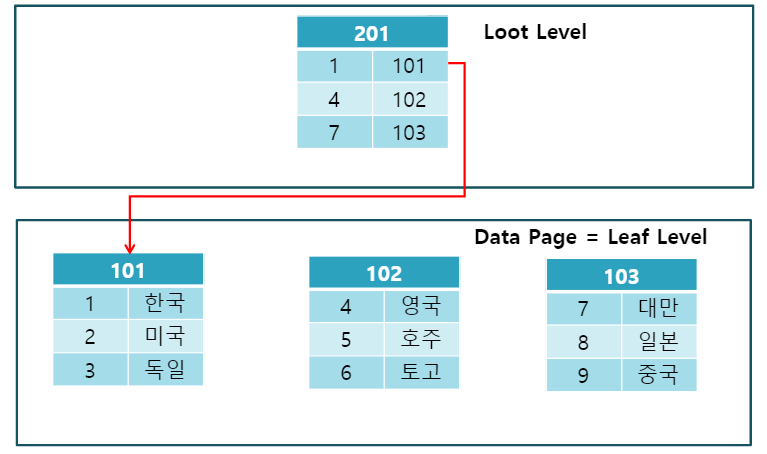
클러스터 형의 반대로 군집화 되어있지 않은 인덱스 타입입니다.
테이블에 저장된 물리적인 순서에 따라 데이터를 정렬하지 않습니다.
논 클러스터형 인덱스는 테이블 데이터와 함께 테이블에 저장되는 것이 아니라 별도의 장소에 저장됩니다.
책의 목차처럼 index 페이지를 따로 나눈 형태와 유사합니다.

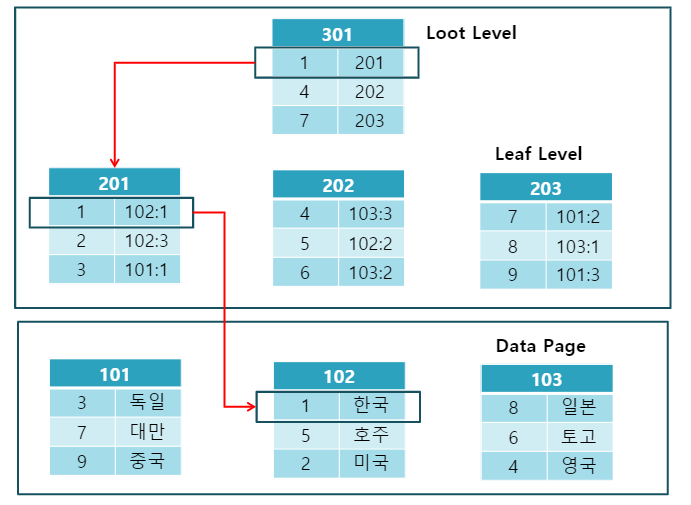
- Non-Clustered 인덱스는 Clustered 구조와는 다르게 Leaf Level과 Data Page가 구분됩니다.
- Data Page의 데이터는 정렬되어 있지 않습니다.
- 즉, 레코드의 원본은 정렬되어 있지 않고, 인덱스 페이지만 정렬됩니다.
- Non-Clustered Index는 데이터 페이지를 건드리지 않고, 별도의 장소에 인덱스 페이지를 생성합니다.
- 인덱스 페이지의 Leaf Page에 index로 구성한 열을 정렬한 후 위치 포인터(RID)를 생성합니다.
- RID: “페이지 번호” + “슬롯 번호” + “파일 ID”
- 페이지 번호 : 데이터가 저장된 디스크 페이지의 번호
- 슬롯 번호 : 해당 페이지 내에서 행이 위치한 슬롯의 번호
- 파일 ID : 데이터 파일을 구분하는 ID (일부 DB에서 사용됨)
어떤 경우에 생성해야 하는지
- where 절이나 join 절과 같이 조건문을 활용하여 테이블을 필터링하고자 할 때
- 데이터가 자주 업데이트 될 때
- 특정 컬럼이 쿼리에서 자주 사용될 때
참고자료
Clustered vs NonClustered (index 개념)
'CS > Database' 카테고리의 다른 글
| MySQL Lock과 트랜잭션 격리 수준 정리 | 데이터베이스 Lock & Isolation Level 이해 (0) | 2025.03.16 |
|---|---|
| 데이터베이스 B Tree 자료구조란, 데이터 삽입 과정 및 AVL Tree와 차이 이해하기 (0) | 2025.01.04 |
| 데이터베이스 인덱스 종류와 원리: 희소 인덱스, 밀집 인덱스, 클러스터링 인덱스 (0) | 2024.02.28 |
| [DB] 데이터베이스의 원칙과 ACID, RDBMS와 NOSQL의 차이점 이해하기 (1) | 2023.10.09 |
| [DB] 데이터베이스 정규화란, 함수적 종속성, 이행적 종속성 - 제1정규화, 제2정규화, 제3정규화, BCNF (0) | 2022.10.09 |
Index
인덱스 파일은 데이터베이스에서 쿼리 성능을 향상시키기 위해 테이블의 특정 컬럼 값과 해당 행의 위치(Pointer)를 저장합니다.
인덱스는 테이블의 데이터를 효율적으로 검색하기 위한 자료구조를 활용합니다. (B-Tree, Hash)
Indexed Column Value
인덱스가 설정된 컬럼의 실제 값들이 저장됩니다.
해당 값을 이용해 데이터베이스가 특정 행을 찾는 데 필요한 정보로 사용합니다.
Indexed Column Value: 101, 102, 103, 104, ...
Row Pointer
인덱스 파일에는 해당 인덱스 키 값이 테이블의 어느 행에 위치하는지에 대한 정보를 나타내는 포인터가 함께 저장됩니다.
해당 포인터는 테이블의 실제 데이터 행을 가리킵니다.
Indexed Column Value: 101 -> Row 5
Indexed Column Value: 102 -> Row 2
Indexed Column Value: 103 -> Row 7
복합 인덱스인 경우
복합 인덱스의 인덱스 파일에는 각 컬럼의 값이 순서대로 결합된 형태로 저장됩니다.
인덱스 파일은 첫 번째 컬럼 값에 따라 정렬되며, 그다음 두 번째 컬럼 값에 따라 정렬됩니다.
(department, job_title) -> Row Pointer
(HR, Manager) -> Row 5
(HR, Analyst) -> Row 2
(Sales, Manager) -> Row 7
Clustered Index
클러스터드 인덱스는 데이터가 테이블에 물리적으로 저장되는 순서를 정의합니다.
- 클러스터형 인덱스는 특정 컬럼을 기준으로 데이터들을 정렬시킵니다.
- id가 클러스터형 인덱스로 지정되어, id 값을 기준으로 데이터들이 정렬되어 있습니다.
테이블 데이터는 오직 한 가지의 방법으로만 정렬되기에, 테이블 당 하나의 클러스터 형 인덱스만 존재할 수 있습니다.
- Primary Key의 제약 조건은 클러스터 된 인덱스를 자동으로 생성합니다.
어떤 경우에 생성해야 하는지
- 테이블 데이터가 자주 업데이트 되지 않는 경우
- 중간에 새로운 데이터가 들어오는데 뒤에 수백만 개의 데이터가 존재하는 경우, index가 군집화되어 있으므로 모든 데이터가 한 칸씩 이동하게 되어 많은 비용이 발생합니다.
- 항상 정렬된 방식으로 데이터를 반환하는 경우
- 테이블이 이미 정렬되어 있기에, Order by 절을 활용하지 않아도 된다.
- 읽기 작업이 많은 경우
Non Clustered
클러스터 형의 반대로 군집화 되어있지 않은 인덱스 타입입니다.
테이블에 저장된 물리적인 순서에 따라 데이터를 정렬하지 않습니다.
논 클러스터형 인덱스는 테이블 데이터와 함께 테이블에 저장되는 것이 아니라 별도의 장소에 저장됩니다.
책의 목차처럼 index 페이지를 따로 나눈 형태와 유사합니다.
- Non-Clustered 인덱스는 Clustered 구조와는 다르게 Leaf Level과 Data Page가 구분됩니다.
- Data Page의 데이터는 정렬되어 있지 않습니다.
- 즉, 레코드의 원본은 정렬되어 있지 않고, 인덱스 페이지만 정렬됩니다.
- Non-Clustered Index는 데이터 페이지를 건드리지 않고, 별도의 장소에 인덱스 페이지를 생성합니다.
- 인덱스 페이지의 Leaf Page에 index로 구성한 열을 정렬한 후 위치 포인터(RID)를 생성합니다.
- RID: “페이지 번호” + “슬롯 번호” + “파일 ID”
- 페이지 번호 : 데이터가 저장된 디스크 페이지의 번호
- 슬롯 번호 : 해당 페이지 내에서 행이 위치한 슬롯의 번호
- 파일 ID : 데이터 파일을 구분하는 ID (일부 DB에서 사용됨)
어떤 경우에 생성해야 하는지
- where 절이나 join 절과 같이 조건문을 활용하여 테이블을 필터링하고자 할 때
- 데이터가 자주 업데이트 될 때
- 특정 컬럼이 쿼리에서 자주 사용될 때
참고자료
Clustered vs NonClustered (index 개념)
'CS > Database' 카테고리의 다른 글
| MySQL Lock과 트랜잭션 격리 수준 정리 | 데이터베이스 Lock & Isolation Level 이해 (0) | 2025.03.16 |
|---|---|
| 데이터베이스 B Tree 자료구조란, 데이터 삽입 과정 및 AVL Tree와 차이 이해하기 (0) | 2025.01.04 |
| 데이터베이스 인덱스 종류와 원리: 희소 인덱스, 밀집 인덱스, 클러스터링 인덱스 (0) | 2024.02.28 |
| [DB] 데이터베이스의 원칙과 ACID, RDBMS와 NOSQL의 차이점 이해하기 (1) | 2023.10.09 |
| [DB] 데이터베이스 정규화란, 함수적 종속성, 이행적 종속성 - 제1정규화, 제2정규화, 제3정규화, BCNF (0) | 2022.10.09 |