
파이썬 머신러닝 가이드 책을 참고하였습니다.
목차
1. KFold
2. Stratified KFold
3. cross_val_score()
○ 데이터 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
import numpy as np
iris = load_iris()
features = iris.data
label = iris.target
dt_clf = DecisionClassifier(random_state=156)(1) 교차검증 (KFold)
from sklearn.model_selection import KFold
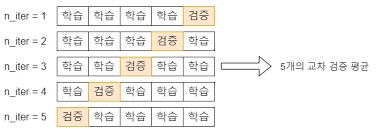
kfold = KFold(n_splits=5)모델 학습 시 과적합에 취약한 약점이 있습니다.
과적합은 모델이 학습 데이터에만 과도하게 최적화되어, 실제 예측을 다른 데이터로 수행할 경우에는 예측 성능이 과도하게 떨어지는 것을 의미합니다.
이를 막기 위해 교차 검증은 학습 데이터를 다시 분할하여 학습 데이터와 학습된 모델의 성능을 일차 평가하는 검증 데이터로 나눕니다.
교차검증은 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행하는 것을 의미합니다.
# 교차 검증 시 각 정확도 저장
cv_accuracy = []
# 교차 검증 횟수
n_iter = 0
for train_index, test_index in kfold.split(features):
# kfold.split() 으로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터 추출
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
# 학습 및 예측
df_clf.fit(x_train, y_train)
pred = df_clf.predict(x_test)
# 반복 시마다 정확도 측정
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
cv_accuarcy.append(accuracy)(2) Stratified KFold 교차검증
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits = 3)
n_iter = 0
cv_accuracy = []
for train_index, test_index in skf.split(features, label):
# kfold.split() 으로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터 추출
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
# 학습 및 예측
df_clf.fit(x_train, y_train)
pred = df_clf.predict(x_test)
# 반복 시마다 정확도 측정
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
cv_accuarcy.append(accuracy)Stratified KFold는 불균형한 분포를 가진 레이블 데이터 집합을 위한 K 폴드 방식이다.
Stratified KFold는 레이블 데이터 분포도에 따라 학습 및 검증 데이터를 나누기 때문에 split() 메서드에 인자로 피처 데이터뿐만 아니라 레이블 데이터 세트도 반드시 입력해주어야 합니다.
(3) 교차 검증을 보다 간편하게 해주는 API - cross_val_score()
주요 파라미터 cross_val_score(df_clf, data, label, scoring='accuracy', cv=3 )
estimator : 알고리즘 클래스 / x : 피처 데이터 세트 / y : 레이블 데이터 세트
scroing : 예측 성능 평가 지표 / cv : 교차 검증 폴드 수
from sklearn.model_selection import cross_val_score
scores = cross_val_score(df_clf, features, label, scoring='accuracy', cv=3)
[ML] 머신러닝 모델의 오차 행렬, 정확도, 정밀도, 재현율 구하기
[ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기
목차 1. 오차 행렬 2. 정확도 3. 정밀도 4. 재현율 (1) 오차 행렬 : 이진 분류에서 성능 지표로 활용되며, 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표이다.
kylo8.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| [ML] 머신러닝 결정트리 (DecisionTreeClassifier, DecisionTreeRegressor) (0) | 2022.04.06 |
|---|---|
| [ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기 (0) | 2022.04.05 |
| [ML] 머신러닝 기초 다지기 / fit, predict, train_test_split, accuracy_score (0) | 2022.04.04 |
| [ML] 머신러닝 분류 알고리즘 - SVM (0) | 2022.03.02 |
| KNN 분류 알고리즘 개념과 구현: 머신러닝에서 K-최근접 이웃 활용법 (0) | 2022.03.02 |
파이썬 머신러닝 가이드 책을 참고하였습니다.
목차
1. KFold
2. Stratified KFold
3. cross_val_score()
○ 데이터 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
import numpy as np
iris = load_iris()
features = iris.data
label = iris.target
dt_clf = DecisionClassifier(random_state=156)(1) 교차검증 (KFold)
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)모델 학습 시 과적합에 취약한 약점이 있습니다.
과적합은 모델이 학습 데이터에만 과도하게 최적화되어, 실제 예측을 다른 데이터로 수행할 경우에는 예측 성능이 과도하게 떨어지는 것을 의미합니다.
이를 막기 위해 교차 검증은 학습 데이터를 다시 분할하여 학습 데이터와 학습된 모델의 성능을 일차 평가하는 검증 데이터로 나눕니다.
교차검증은 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행하는 것을 의미합니다.
# 교차 검증 시 각 정확도 저장
cv_accuracy = []
# 교차 검증 횟수
n_iter = 0
for train_index, test_index in kfold.split(features):
# kfold.split() 으로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터 추출
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
# 학습 및 예측
df_clf.fit(x_train, y_train)
pred = df_clf.predict(x_test)
# 반복 시마다 정확도 측정
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
cv_accuarcy.append(accuracy)(2) Stratified KFold 교차검증
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits = 3)
n_iter = 0
cv_accuracy = []
for train_index, test_index in skf.split(features, label):
# kfold.split() 으로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터 추출
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
# 학습 및 예측
df_clf.fit(x_train, y_train)
pred = df_clf.predict(x_test)
# 반복 시마다 정확도 측정
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
cv_accuarcy.append(accuracy)Stratified KFold는 불균형한 분포를 가진 레이블 데이터 집합을 위한 K 폴드 방식이다.
Stratified KFold는 레이블 데이터 분포도에 따라 학습 및 검증 데이터를 나누기 때문에 split() 메서드에 인자로 피처 데이터뿐만 아니라 레이블 데이터 세트도 반드시 입력해주어야 합니다.
(3) 교차 검증을 보다 간편하게 해주는 API - cross_val_score()
주요 파라미터 cross_val_score(df_clf, data, label, scoring='accuracy', cv=3 )
estimator : 알고리즘 클래스 / x : 피처 데이터 세트 / y : 레이블 데이터 세트
scroing : 예측 성능 평가 지표 / cv : 교차 검증 폴드 수
from sklearn.model_selection import cross_val_score
scores = cross_val_score(df_clf, features, label, scoring='accuracy', cv=3)
[ML] 머신러닝 모델의 오차 행렬, 정확도, 정밀도, 재현율 구하기
[ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기
목차 1. 오차 행렬 2. 정확도 3. 정밀도 4. 재현율 (1) 오차 행렬 : 이진 분류에서 성능 지표로 활용되며, 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표이다.
kylo8.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| [ML] 머신러닝 결정트리 (DecisionTreeClassifier, DecisionTreeRegressor) (0) | 2022.04.06 |
|---|---|
| [ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기 (0) | 2022.04.05 |
| [ML] 머신러닝 기초 다지기 / fit, predict, train_test_split, accuracy_score (0) | 2022.04.04 |
| [ML] 머신러닝 분류 알고리즘 - SVM (0) | 2022.03.02 |
| KNN 분류 알고리즘 개념과 구현: 머신러닝에서 K-최근접 이웃 활용법 (0) | 2022.03.02 |