
파이썬 머신러닝 완벽 가이드 책을 참고하였습니다.
(1) DecisionTreeClassifier, DecisionTreeRegressor 결정 트리
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만든다.
일반적으로 if, else를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘이라고도 할 수 있다.
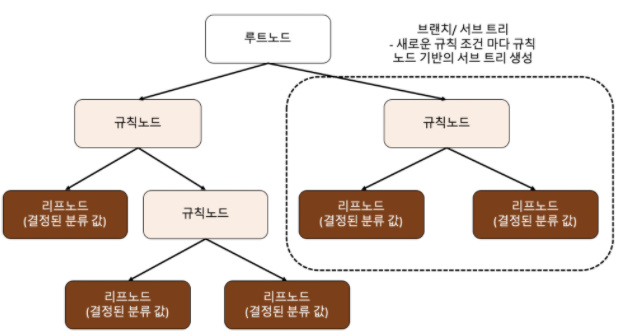
* 규칙 노드 : 규칙 조건을 의미
* 리프 노드 : 결정된 클래스 값
* 서브 트리 : 새로운 규칙마다 생겨나는 트리를 의미
장점
1. 직관적으로 이해하기 쉬운 알고리즘이다.
2. 피처의 스케일링이나 정규화 등의 사전 가공 영향도가 크지 않다.
단점
1. 많은 규칙이 있으면 분류를 결정하는 방식이 복잡해진다. -> 과적합으로 이어지기 쉽다.
이를 극복하기 위해 트리의 크기를 사전에 제한하는 튜닝이 필요하다.
(2) 결정트리 파라미터
* min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는 데 사용된다.
* min_samples_leaf : 리프 노드가 되기 위한 최소한의 샘플 데이터 수를 의미한다.
* max_features : 최적의 분할을 위해 고려할 최대 피처 개수
* max_depth : 트리의 최대 깊이를 규정한다. min_samples_split보다 작아질 때까지 계속 깊이를 증가시킨다.
(과적 합 방지에 용이)
* max_leaf_nodes : 말단 노드의 최대 개수
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 모델 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 모델 학습 및 예측
dt_clf.fit(x_train, y_train)
pred = df_clf.predcit(x_test)
# DecisionTreeClassifier의 하이퍼 파라미터 추출하기
print(dt_clf.get_params())(3) 결정 트리 하이퍼 파라미터 튜닝해보기
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [4, 8, 12, 16, 20 ]
'min_samples_split' : [16, 24]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5)
grid_cv.fit(x_train, y_train)
print('GridSearchCV 최고 평균 정확도 수치 : {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터 : grid_cv.best_params_)GridSearchCV를 이용해 모델의 튜닝과 교차 검증을 동시에 실행한다.
파라미터
* best_score_ : 학습된 GridSearchCV 모델 중 최고의 평균 정확도 수치를 출력한다.
* best_params_ : 최적의 하이퍼 파라미터를 출력한다.
(4) 피처 중요도 파악하기 feature_importances_
사이킷런은 결정 트리 알고리즘이 학습을 통해 규칙을 정하는 데 있어 피처 한 역할 지표를 feature_importances_ 속성으로 제공한다.
import seaborn as sns
import numpy as np
print("Feature importances :".format(np.round(df_clf.feature_importances_,3)))
# seaborn을 이용해 피처의 중요도 시각화하기
for name, value in zip(data.features_names, dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value)
# 시각화
sns.barplot(x=df_clf.feature_importances_, y=data.feature_names)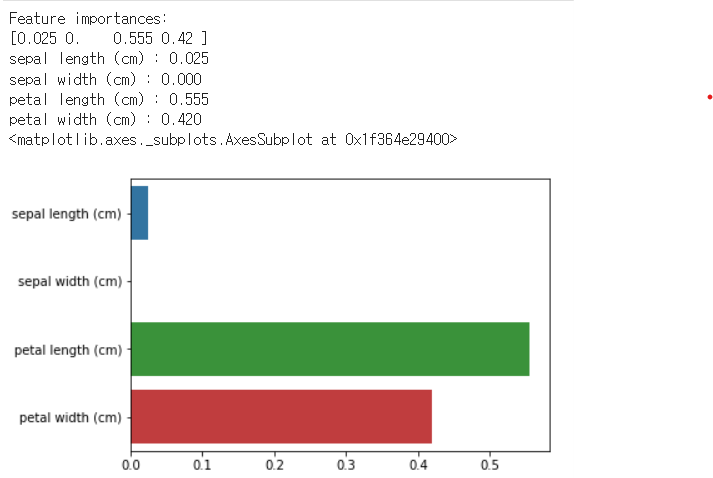
[ML] 머신러닝 모델의 오차 행렬, 정확도, 정밀도, 재현율 구하기
[ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기
목차 1. 오차 행렬 2. 정확도 3. 정밀도 4. 재현율 (1) 오차 행렬 : 이진 분류에서 성능 지표로 활용되며, 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표이다.
kylo8.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| [ML] 머신러닝 - 부스팅 GBM, XGBoost, LightGBM (0) | 2022.04.09 |
|---|---|
| [ML] 머신러닝 - 앙상블 ( 보팅, 배깅 ) (0) | 2022.04.06 |
| [ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기 (0) | 2022.04.05 |
| [ML] 머신러닝 교차 검증- KFold, Stratified KFold, cross_val_score() (0) | 2022.04.04 |
| [ML] 머신러닝 기초 다지기 / fit, predict, train_test_split, accuracy_score (0) | 2022.04.04 |
파이썬 머신러닝 완벽 가이드 책을 참고하였습니다.
(1) DecisionTreeClassifier, DecisionTreeRegressor 결정 트리
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만든다.
일반적으로 if, else를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘이라고도 할 수 있다.
* 규칙 노드 : 규칙 조건을 의미
* 리프 노드 : 결정된 클래스 값
* 서브 트리 : 새로운 규칙마다 생겨나는 트리를 의미
장점
1. 직관적으로 이해하기 쉬운 알고리즘이다.
2. 피처의 스케일링이나 정규화 등의 사전 가공 영향도가 크지 않다.
단점
1. 많은 규칙이 있으면 분류를 결정하는 방식이 복잡해진다. -> 과적합으로 이어지기 쉽다.
이를 극복하기 위해 트리의 크기를 사전에 제한하는 튜닝이 필요하다.
(2) 결정트리 파라미터
* min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는 데 사용된다.
* min_samples_leaf : 리프 노드가 되기 위한 최소한의 샘플 데이터 수를 의미한다.
* max_features : 최적의 분할을 위해 고려할 최대 피처 개수
* max_depth : 트리의 최대 깊이를 규정한다. min_samples_split보다 작아질 때까지 계속 깊이를 증가시킨다.
(과적 합 방지에 용이)
* max_leaf_nodes : 말단 노드의 최대 개수
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 모델 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 모델 학습 및 예측
dt_clf.fit(x_train, y_train)
pred = df_clf.predcit(x_test)
# DecisionTreeClassifier의 하이퍼 파라미터 추출하기
print(dt_clf.get_params())(3) 결정 트리 하이퍼 파라미터 튜닝해보기
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [4, 8, 12, 16, 20 ]
'min_samples_split' : [16, 24]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5)
grid_cv.fit(x_train, y_train)
print('GridSearchCV 최고 평균 정확도 수치 : {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터 : grid_cv.best_params_)GridSearchCV를 이용해 모델의 튜닝과 교차 검증을 동시에 실행한다.
파라미터
* best_score_ : 학습된 GridSearchCV 모델 중 최고의 평균 정확도 수치를 출력한다.
* best_params_ : 최적의 하이퍼 파라미터를 출력한다.
(4) 피처 중요도 파악하기 feature_importances_
사이킷런은 결정 트리 알고리즘이 학습을 통해 규칙을 정하는 데 있어 피처 한 역할 지표를 feature_importances_ 속성으로 제공한다.
import seaborn as sns
import numpy as np
print("Feature importances :".format(np.round(df_clf.feature_importances_,3)))
# seaborn을 이용해 피처의 중요도 시각화하기
for name, value in zip(data.features_names, dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value)
# 시각화
sns.barplot(x=df_clf.feature_importances_, y=data.feature_names)
[ML] 머신러닝 모델의 오차 행렬, 정확도, 정밀도, 재현율 구하기
[ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기
목차 1. 오차 행렬 2. 정확도 3. 정밀도 4. 재현율 (1) 오차 행렬 : 이진 분류에서 성능 지표로 활용되며, 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표이다.
kylo8.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| [ML] 머신러닝 - 부스팅 GBM, XGBoost, LightGBM (0) | 2022.04.09 |
|---|---|
| [ML] 머신러닝 - 앙상블 ( 보팅, 배깅 ) (0) | 2022.04.06 |
| [ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기 (0) | 2022.04.05 |
| [ML] 머신러닝 교차 검증- KFold, Stratified KFold, cross_val_score() (0) | 2022.04.04 |
| [ML] 머신러닝 기초 다지기 / fit, predict, train_test_split, accuracy_score (0) | 2022.04.04 |