
목차
1. 오차 행렬
2. 정확도
3. 정밀도
4. 재현율
(1) 오차 행렬
: 이진 분류에서 성능 지표로 활용되며, 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표이다.
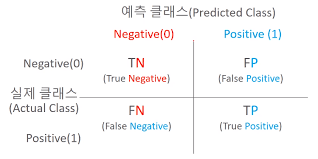
* TN는 예측값을 Negative 값 0으로 예측했고 실제 값 역시 Negative 값 0
* FP는 예측값을 Positive 값 1로 예측했는데 실제 값은 Negative 값 0
* FN은 예측값을 Negative 값 0으로 예측했는데 실제 값은 Positive 값 1
* TP는 예측값을 Positive 값 1로 예측했는데 실제 값 Positive 값 1
# 오차 행렬 구해보기
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, pred))○ 데이터 불러오기
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
x_train, x_test, y_train, y_test = train_test_split(x.data, x.target, test_size=0.2, random_state=156)
# 로지스틱 회귀로 학습, 예측 및 평가 수행
lr_clf = LogisticRegression()
lr_clf.fit(x_train, y_train)
pred = lr_clf.predict(x_test)
pred_proba = lr_clf.predict_proba(x_test)[:,1]* predict()는 predict_proba() 호출 결과로 반환된 배열에서 분류 결정 임계값보다 큰 값이 들어 있는 칼럼의 위치를 받아서 최종적으로 예측 클래스를 결정하는 API이다.
( 추가 설명 )
from sklearn.preprocessing import Binarizer
X = [[ 1, -1, 2],
[ 2, 0, 0],
[ 0, 1.1, 1.2]]
# threshold 기준값보다 같거나 작으면 0을, 크면 1을 반환
binarizer = Binarizer(threshold=1.1)
print(binarizer.fit_transform(X))결과
[[0. 0. 1.]
[1. 0. 0.]
[0. 0. 1.]](2) 정확도(Accuracy)
: 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
( TN + TP ) / ( TN + FP + FN + TP )
from sklearn.metrics import accuracy_score
print(accuracy_acore(y_test, pred))accuracy_score() 파라미터로
y_test : 테스트 레이블 값과 pred : 테스트 피처 데이터로 예측한 값을 넣어주어 정확도를 구합니다.
(3) 정밀도
: 예측을 Positive로 한 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 의미한다.
TP / ( FP + TP )
from sklearn.metrics import precision_score
print(precision_acore(y_test, pred))* 실제 Negative 음성인 데이터 예측을 Positive 양성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 중요하게 사용된다.
ex) 스팸 메일 여부 ( 일반(Negative) 메일을 스팸(Positive) 메일로 분류하면 문제가 발생)
(4) 재현율
: 실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 의미한다.
TP / ( FN + TP )
from sklearn.metrics import recall_score
print(recall_acore(y_test, pred))* 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 중요하다.
ex) 보험사기, 금융 사기 ( 금융 거래 사기인 Positive 건을 Negative로 잘못 판단하게 되면 큰 손해 발생 )
(5) F1 Score
: 정밀도와 재현율을 결합한 지표이다.
정밀도와 재현율의 수치가 적절하게 조합돼 분류의 종합적인 성능 평가에 사용될 수 있는 평가 지표이다.

from sklearn.metrics import f1_score
print(f1_acore(y_test, pred))(6) roc_auc_score
: ROC 곡선과 이에 기반한 AUC 스코어로 이진 분류의 예측 성능 측정에서 중요하게 사용되는 지표이다.
ROC 곡선은 FPR ( False Positive Rate )이 변할 때 TPR ( True Positive Rate )이 어떻게 변하는지를 나타내는 곡선이다.
TPR은 재현율을 나타내며, FPR은 FP / ( FP + TN ) 즉, 실제 Negative 값들 중에서 잘못 예측한 False Positive값의 비율을 나타낸다.
from sklearn.metrics import roc_auc_score
print(roc_auc_acore(y_test, pred_proba))
[machine learning] - 머신러닝 - 회귀, 다항 회귀, MSE, RMSE
머신러닝 - 회귀, 다항회귀, MSE, RMSE
파이썬 머신러닝 가이드 책을 참고하였습니다. ● 회귀 머신러닝의 (선형)회귀는 실제 값과 예측값의 차이를 최소화하는 식을 찾는 것으로, y=wx+b의 식에서 독립변수의 값에 영향을 미치는 회귀
kylo8.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| [ML] 머신러닝 - 앙상블 ( 보팅, 배깅 ) (0) | 2022.04.06 |
|---|---|
| [ML] 머신러닝 결정트리 (DecisionTreeClassifier, DecisionTreeRegressor) (0) | 2022.04.06 |
| [ML] 머신러닝 교차 검증- KFold, Stratified KFold, cross_val_score() (0) | 2022.04.04 |
| [ML] 머신러닝 기초 다지기 / fit, predict, train_test_split, accuracy_score (0) | 2022.04.04 |
| [ML] 머신러닝 분류 알고리즘 - SVM (0) | 2022.03.02 |
목차
1. 오차 행렬
2. 정확도
3. 정밀도
4. 재현율
(1) 오차 행렬
: 이진 분류에서 성능 지표로 활용되며, 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표이다.
* TN는 예측값을 Negative 값 0으로 예측했고 실제 값 역시 Negative 값 0
* FP는 예측값을 Positive 값 1로 예측했는데 실제 값은 Negative 값 0
* FN은 예측값을 Negative 값 0으로 예측했는데 실제 값은 Positive 값 1
* TP는 예측값을 Positive 값 1로 예측했는데 실제 값 Positive 값 1
# 오차 행렬 구해보기
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, pred))○ 데이터 불러오기
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
x_train, x_test, y_train, y_test = train_test_split(x.data, x.target, test_size=0.2, random_state=156)
# 로지스틱 회귀로 학습, 예측 및 평가 수행
lr_clf = LogisticRegression()
lr_clf.fit(x_train, y_train)
pred = lr_clf.predict(x_test)
pred_proba = lr_clf.predict_proba(x_test)[:,1]* predict()는 predict_proba() 호출 결과로 반환된 배열에서 분류 결정 임계값보다 큰 값이 들어 있는 칼럼의 위치를 받아서 최종적으로 예측 클래스를 결정하는 API이다.
( 추가 설명 )
from sklearn.preprocessing import Binarizer
X = [[ 1, -1, 2],
[ 2, 0, 0],
[ 0, 1.1, 1.2]]
# threshold 기준값보다 같거나 작으면 0을, 크면 1을 반환
binarizer = Binarizer(threshold=1.1)
print(binarizer.fit_transform(X))결과
[[0. 0. 1.]
[1. 0. 0.]
[0. 0. 1.]](2) 정확도(Accuracy)
: 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
( TN + TP ) / ( TN + FP + FN + TP )
from sklearn.metrics import accuracy_score
print(accuracy_acore(y_test, pred))accuracy_score() 파라미터로
y_test : 테스트 레이블 값과 pred : 테스트 피처 데이터로 예측한 값을 넣어주어 정확도를 구합니다.
(3) 정밀도
: 예측을 Positive로 한 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 의미한다.
TP / ( FP + TP )
from sklearn.metrics import precision_score
print(precision_acore(y_test, pred))* 실제 Negative 음성인 데이터 예측을 Positive 양성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 중요하게 사용된다.
ex) 스팸 메일 여부 ( 일반(Negative) 메일을 스팸(Positive) 메일로 분류하면 문제가 발생)
(4) 재현율
: 실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 의미한다.
TP / ( FN + TP )
from sklearn.metrics import recall_score
print(recall_acore(y_test, pred))* 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 중요하다.
ex) 보험사기, 금융 사기 ( 금융 거래 사기인 Positive 건을 Negative로 잘못 판단하게 되면 큰 손해 발생 )
(5) F1 Score
: 정밀도와 재현율을 결합한 지표이다.
정밀도와 재현율의 수치가 적절하게 조합돼 분류의 종합적인 성능 평가에 사용될 수 있는 평가 지표이다.
from sklearn.metrics import f1_score
print(f1_acore(y_test, pred))(6) roc_auc_score
: ROC 곡선과 이에 기반한 AUC 스코어로 이진 분류의 예측 성능 측정에서 중요하게 사용되는 지표이다.
ROC 곡선은 FPR ( False Positive Rate )이 변할 때 TPR ( True Positive Rate )이 어떻게 변하는지를 나타내는 곡선이다.
TPR은 재현율을 나타내며, FPR은 FP / ( FP + TN ) 즉, 실제 Negative 값들 중에서 잘못 예측한 False Positive값의 비율을 나타낸다.
from sklearn.metrics import roc_auc_score
print(roc_auc_acore(y_test, pred_proba))
[machine learning] - 머신러닝 - 회귀, 다항 회귀, MSE, RMSE
머신러닝 - 회귀, 다항회귀, MSE, RMSE
파이썬 머신러닝 가이드 책을 참고하였습니다. ● 회귀 머신러닝의 (선형)회귀는 실제 값과 예측값의 차이를 최소화하는 식을 찾는 것으로, y=wx+b의 식에서 독립변수의 값에 영향을 미치는 회귀
kylo8.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| [ML] 머신러닝 - 앙상블 ( 보팅, 배깅 ) (0) | 2022.04.06 |
|---|---|
| [ML] 머신러닝 결정트리 (DecisionTreeClassifier, DecisionTreeRegressor) (0) | 2022.04.06 |
| [ML] 머신러닝 교차 검증- KFold, Stratified KFold, cross_val_score() (0) | 2022.04.04 |
| [ML] 머신러닝 기초 다지기 / fit, predict, train_test_split, accuracy_score (0) | 2022.04.04 |
| [ML] 머신러닝 분류 알고리즘 - SVM (0) | 2022.03.02 |