
[ML] 머신러닝 - 앙상블 ( 보팅, 배깅 )
[machine learning] - 머신러닝 - 스태킹 앙상블 머신러닝 - 스태킹 앙상블 파이썬 머신러닝 가이드 책을 참고하였습니다. ● 스태킹 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는
kylo8.tistory.com
파이썬 머신러닝 가이드 책을 참고하였습니다.
목차
1. 부스팅이란
2. GBM
3. XGBoost
4. LightGBM
(1) 부스팅이란
여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식을 말합니다.
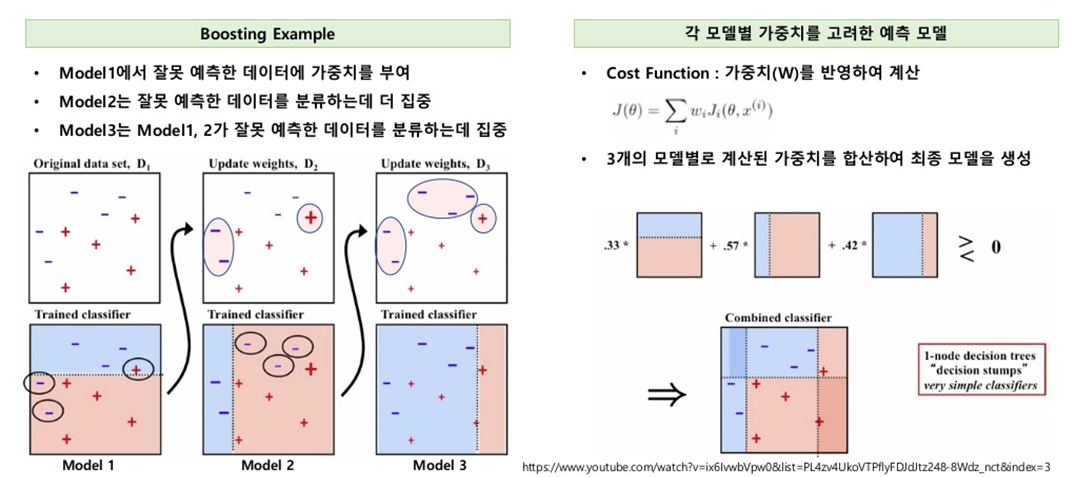
* 첫 번째 약한 학습기가 +, - 로 분류를 하며 잘못 분류된 오류 데이터에는 가중치를 부여한다.
가중치가 부여된 오류 데이터는 다음 약한 학습기가 더 잘 분류할 수 있게 더 크기가 커지게 됩니다.
*두 번째 약한 학습기도 +, - 를 분류하며 잘못 분류된 오류 데이터에 가중치를 부여한다.
위와 같은 방법을 반복하며, 약한 학습기가 순차적으로 오류 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측을 수행한다.
from sklearn.ensemble import GradientBoostingClassifier
gd_clf = GradientBoostingClassifier(random_state=0)
gd_clf.fit(x_train, y_train)
gd_pred = gd_clf.predict(x_test)
gd_accuracy = accuracy_score(y_test, pred)
print(gd_accuracy)(2) GBM
GBM 알고리즘의 장단점
과적합에도 강한 뛰어난 예측 성능을 가지고 있다. 하지만 수행 시간이 오래 걸리는 단점이 있다.
파라미터
* loss : 경사 하강법에서 사용할 비용 함수를 지정한다. (default : 'deviance')
* learning_rate : GBM이 학습을 진행할 때마다 적용하는 학습률 (default : 0.1)
* n_estimators : 약한 학습기 ( weak learner )의 개수 (default : 100)
(3) XGBoost
GBM에 기반하고 있지만, GBM의 단점인 느린 수행 시간 및 과적합 규제 부재 등의 문제를 해결한 뛰어난 알고리즘이다.
병렬 수행 및 다양한 기능으로 빠른 수행 성능을 보장하며 과적합 규제 기능 또한 가지고 있습니다.
반복 수행 시마다 내부적으로 학습 데이터 세트와 평가 데이터 세트에 대한 교차 검증을 수행해 최적화된 반복 수행 횟수를 가질 수 있으며, 결손값을 자체 처리할 수 있는 기능을 가지고 있다.
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learing_rate=0.1, max_depth=3)
xgb_wrapper.fit(x_train, y_train)
w_pred = wgb_wrapper.predict(x_test)
w_accuracy = accuracy_score(y_test, w_pred)
# 정확도 출력
print(w_accuracy)○ XGBoost에서 조기 중단을 수행하기 위해서, 조기 중단 관련 파라미터를 fit()에 입력한다
* early_stopping_rounds : 평가 지표가 향상될 수 있는 반복 횟수를 의미
* eval_metric : 조기 중단을 위한 평가 지표
* eval_set : 성능 평가를 수행할 데이터 세트 ( 성능 평가를 수행할 데이터 세트는 학습 데이터가 아니라 별도의 데이터 세트이어야 한다.)
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learing_rate=0.1, max_depth=3)
evals= [ (x_test, y_test) ]
xgb_wrapper.fit(x_train, y_train, early_stopping_rounds=100, eval_metric="logloss", eval_set=evals)
w_pred = wgb_wrapper.predict(x_test)
w_accuracy = accuracy_score(y_test, w_pred)
# 정확도 출력
print(w_accuracy)
# 주의할 점
eval_set에는 성능 평가를 수행할 데이터가 들어가야 한다고 했습니다.
평가를 위해 데이터 세트로 테스트 데이터 세트를 사용했지만 실제 사용시에는 별개의 데이터 세트를 평가 데이터로 사용하는 것이 좋습니다.
테스트 데이터 세트는 학습 시에는 완전히 알려지지 않은 데이터를 사용해야 하며, 평가에 사용하게 될 시 미리 참고가 되어 과적합 되기 쉽습니다.
위 코드는 예시로 테스트 데이터를 평가용으로 사용했으니, 참고 바랍니다.
[ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기
[ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기
목차 1. 오차 행렬 2. 정확도 3. 정밀도 4. 재현율 (1) 오차 행렬 : 이진 분류에서 성능 지표로 활용되며, 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표이다.
kylo8.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| 머신러닝 스태킹 앙상블 기법 이해와 Python 구현 사례 (0) | 2022.04.09 |
|---|---|
| 불균형 데이터 처리를 위한 언더 샘플링과 오버 샘플링 (0) | 2022.04.09 |
| [ML] 머신러닝 - 앙상블 ( 보팅, 배깅 ) (0) | 2022.04.06 |
| [ML] 머신러닝 결정트리 (DecisionTreeClassifier, DecisionTreeRegressor) (0) | 2022.04.06 |
| [ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기 (0) | 2022.04.05 |
[ML] 머신러닝 - 앙상블 ( 보팅, 배깅 )
[machine learning] - 머신러닝 - 스태킹 앙상블 머신러닝 - 스태킹 앙상블 파이썬 머신러닝 가이드 책을 참고하였습니다. ● 스태킹 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는
kylo8.tistory.com
파이썬 머신러닝 가이드 책을 참고하였습니다.
목차
1. 부스팅이란
2. GBM
3. XGBoost
4. LightGBM
(1) 부스팅이란
여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식을 말합니다.
* 첫 번째 약한 학습기가 +, - 로 분류를 하며 잘못 분류된 오류 데이터에는 가중치를 부여한다.
가중치가 부여된 오류 데이터는 다음 약한 학습기가 더 잘 분류할 수 있게 더 크기가 커지게 됩니다.
*두 번째 약한 학습기도 +, - 를 분류하며 잘못 분류된 오류 데이터에 가중치를 부여한다.
위와 같은 방법을 반복하며, 약한 학습기가 순차적으로 오류 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측을 수행한다.
from sklearn.ensemble import GradientBoostingClassifier
gd_clf = GradientBoostingClassifier(random_state=0)
gd_clf.fit(x_train, y_train)
gd_pred = gd_clf.predict(x_test)
gd_accuracy = accuracy_score(y_test, pred)
print(gd_accuracy)(2) GBM
GBM 알고리즘의 장단점
과적합에도 강한 뛰어난 예측 성능을 가지고 있다. 하지만 수행 시간이 오래 걸리는 단점이 있다.
파라미터
* loss : 경사 하강법에서 사용할 비용 함수를 지정한다. (default : 'deviance')
* learning_rate : GBM이 학습을 진행할 때마다 적용하는 학습률 (default : 0.1)
* n_estimators : 약한 학습기 ( weak learner )의 개수 (default : 100)
(3) XGBoost
GBM에 기반하고 있지만, GBM의 단점인 느린 수행 시간 및 과적합 규제 부재 등의 문제를 해결한 뛰어난 알고리즘이다.
병렬 수행 및 다양한 기능으로 빠른 수행 성능을 보장하며 과적합 규제 기능 또한 가지고 있습니다.
반복 수행 시마다 내부적으로 학습 데이터 세트와 평가 데이터 세트에 대한 교차 검증을 수행해 최적화된 반복 수행 횟수를 가질 수 있으며, 결손값을 자체 처리할 수 있는 기능을 가지고 있다.
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learing_rate=0.1, max_depth=3)
xgb_wrapper.fit(x_train, y_train)
w_pred = wgb_wrapper.predict(x_test)
w_accuracy = accuracy_score(y_test, w_pred)
# 정확도 출력
print(w_accuracy)○ XGBoost에서 조기 중단을 수행하기 위해서, 조기 중단 관련 파라미터를 fit()에 입력한다
* early_stopping_rounds : 평가 지표가 향상될 수 있는 반복 횟수를 의미
* eval_metric : 조기 중단을 위한 평가 지표
* eval_set : 성능 평가를 수행할 데이터 세트 ( 성능 평가를 수행할 데이터 세트는 학습 데이터가 아니라 별도의 데이터 세트이어야 한다.)
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learing_rate=0.1, max_depth=3)
evals= [ (x_test, y_test) ]
xgb_wrapper.fit(x_train, y_train, early_stopping_rounds=100, eval_metric="logloss", eval_set=evals)
w_pred = wgb_wrapper.predict(x_test)
w_accuracy = accuracy_score(y_test, w_pred)
# 정확도 출력
print(w_accuracy)
# 주의할 점
eval_set에는 성능 평가를 수행할 데이터가 들어가야 한다고 했습니다.
평가를 위해 데이터 세트로 테스트 데이터 세트를 사용했지만 실제 사용시에는 별개의 데이터 세트를 평가 데이터로 사용하는 것이 좋습니다.
테스트 데이터 세트는 학습 시에는 완전히 알려지지 않은 데이터를 사용해야 하며, 평가에 사용하게 될 시 미리 참고가 되어 과적합 되기 쉽습니다.
위 코드는 예시로 테스트 데이터를 평가용으로 사용했으니, 참고 바랍니다.
[ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기
[ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기
목차 1. 오차 행렬 2. 정확도 3. 정밀도 4. 재현율 (1) 오차 행렬 : 이진 분류에서 성능 지표로 활용되며, 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표이다.
kylo8.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| 머신러닝 스태킹 앙상블 기법 이해와 Python 구현 사례 (0) | 2022.04.09 |
|---|---|
| 불균형 데이터 처리를 위한 언더 샘플링과 오버 샘플링 (0) | 2022.04.09 |
| [ML] 머신러닝 - 앙상블 ( 보팅, 배깅 ) (0) | 2022.04.06 |
| [ML] 머신러닝 결정트리 (DecisionTreeClassifier, DecisionTreeRegressor) (0) | 2022.04.06 |
| [ML] 머신러닝 모델의 오차행렬, 정확도, 정밀도, 재현율 구하기 (0) | 2022.04.05 |